This is the multi-page printable view of this section. Click here to print.
Latest
- 1: Getting started
- 2: Deployments
- 2.1: Docker Compose
- 2.2: Kubernetes Daemonset
- 2.3: Systemd Bare-Metal
- 3: Building from Source
- 4: Configuration Guide
- 5: Key Feature
- 5.1: Kernel-Wide Insight
- 5.2: Instant Observability
- 5.3: AutoTracing
- 5.4: Continuous Profiling
- 5.5: Hardware Events
- 6: Best Practice
- 6.1: Storage
- 6.2: Data Source Configuration
- 6.3: Events Watch
- 6.4: Profiling
- 6.5: Network Drop Monitoring (dropwatch)
- 7: Development
- 7.1: Framework
- 7.2: Add Metrics
- 7.3: Add Event
- 7.4: Add Autotracing
- 7.5: Integration Test
- 8: FAQ
- 9: Contribute
- 9.1: Code Contributions
- 10: Change Log
1 - Getting started
To help users quickly experience and deploy HUATUO, this document is divided into three sections: Quick Experience,Quick Start,Compilation & Deployment.
1. Quick Experience
This section helps you quickly explore the frontend capabilities. You can directly access demo station, such as viewing exception event overviews, exception event context information, metric curves, etc. (Account: huatuo passwd: huatuo1024).

2. Quick Start
2.1 Quick Run
If you want to understand the underlying principles and deploy HUATUO to your own monitoring system, you can start pre-compiled container images via Docker (Note: This method disables container information retrieval and ES storage functionality by default).
-
Direct Execution:
$ docker run --privileged --cgroupns=host --network=host -v /sys:/sys -v /proc:/proc -v /run:/run huatuo/huatuo-bamai:latest -
Metric Collection:In another terminal, collect metrics
$ curl -s localhost:19704/metrics -
View Exception Events (Events, AutoTracing):HUATUO stores collected kernel exception event information in ES (disabled by default) while retaining a copy in the local directory
huatuo-local. Note: Typically, no files exist in this path (systems in normal state don’t trigger event collection). You can generate events by creating exception scenarios or modifying configuration thresholds.
2.2 Quick Setup
If you want to further understand HUATUO’s operational mechanisms, architecture design, monitoring dashboard, and custom deployment, you can quickly set up a complete local environment using docker compose.
$ docker compose --project-directory ./build/docker up
This command pulls the latest images and starts components including elasticsearch, prometheus, grafana,huatuo-bamai. After successful command execution, open your browser and visit http://localhost:3000 to access the monitoring dashboard (Grafana default admin account: admin, password: admin; Since your system is in normal state, the Events and AutoTracing dashboards typically won’t display data).
3. Compilation & Deployment
3.1 Compilation
To isolate the developer’s local environment and simplify the compilation process, we provide containerized compilation. You can directly use docker build to construct the completed image (including the underlying collector huatuo-bamai, BPF objects, tools, etc.). Run the following command in the project root directory:
$ docker build --network host -t huatuo/huatuo-bamai:latest .
3.2 Execution
-
Run container:
$ docker run --privileged --cgroupns=host --network=host -v /sys:/sys -v /proc:/proc -v /run:/run huatuo/huatuo-bamai:latest -
Or copy all files from the container path
/home/huatuo-bamaiand run manually locally:$ ./huatuo-bamai --region example --config huatuo-bamai.conf -
Management: Can be managed using systemd/supervisord/k8s-DaemonSet, etc.
3.3 Configuration
-
Container Information Configuration
HUATUO obtains POD/container information by calling the kubelet interface. Configure the access interface and certificates according to your actual environment. Empty configuration "" indicates disabling this functionality.
[Pod] KubeletPodListURL = "http://127.0.0.1:10255/pods" KubeletPodListHTTPSURL = "https://127.0.0.1:10250/pods" KubeletPodClientCertPath = "/var/lib/kubelet/pki/kubelet-client-current.pem" -
Storage Configuration
-
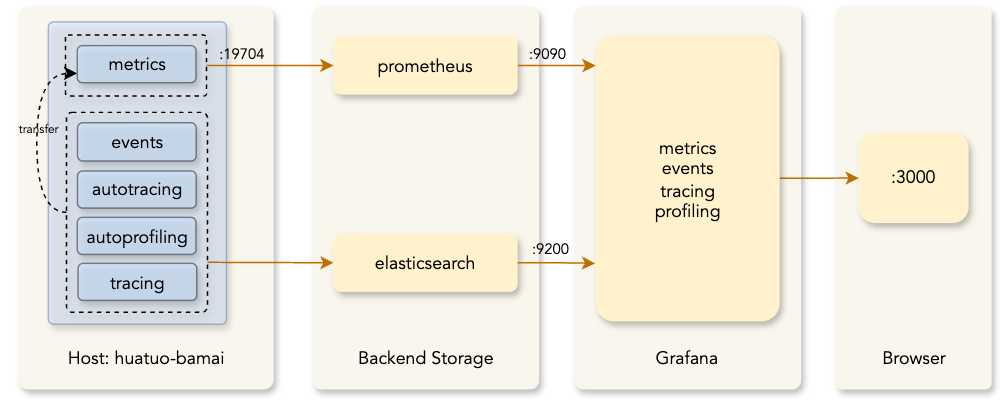
Metric Storage (Metric): All metrics are stored in Prometheus. You can access the :19704/metrics interface to obtain metrics.
-
Exception Event Storage (Events, AutoTracing): All kernel events and AutoTracing events are stored in ES. Note: If the configuration is empty, ES storage is not activated, and events are only stored in the local directory
huatuo-local.ES storage configuration is as follows:
[Storage.ES] Address = "http://127.0.0.1:9200" Username = "elastic" Password = "huatuo-bamai" Index = "huatuo_bamai"Local storage configuration is as follows:
# tracer's record data # Path: all but the last element of path for per tracer # RotationSize: the maximum size in Megabytes of a record file before it gets rotated for per subsystem # MaxRotation: the maximum number of old log files to retain for per subsystem [Storage.LocalFile] Path = "huatuo-local" RotationSize = 100 MaxRotation = 10
-
-
Event Thresholds
All kernel event collections (Events and AutoTracing) can have configurable trigger thresholds. The default thresholds are empirical data repeatedly validated in actual production environments. You can modify thresholds in huatuo-bamai.conf according to your requirements.
-
Resource Limits
To ensure host machine stability, we have implemented resource limits for the collector. LimitInitCPU represents CPU resources occupied during collector startup, while LimitCPU/LimitMem represent resource limits for normal operation after successful startup:
[RuntimeCgroup] LimitInitCPU = 0.5 LimitCPU = 2.0 # limit memory (MB) LimitMem = 2048
2 - Deployments
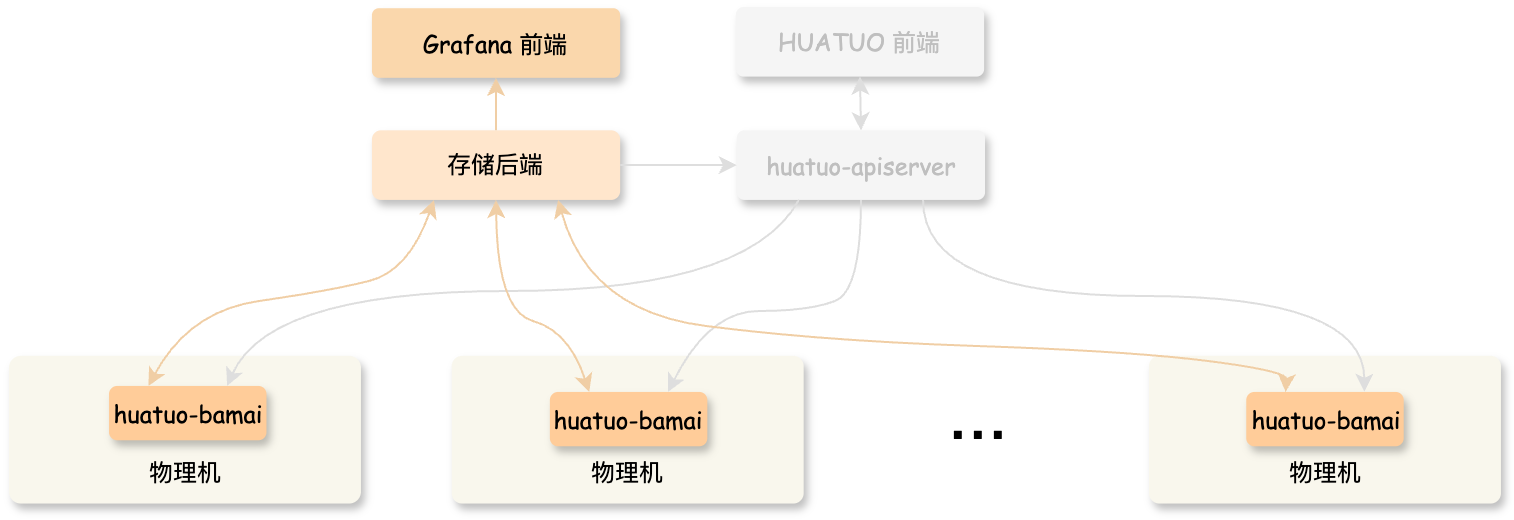
The HUATUO collector huatuo-bamai runs on physical machines or VMs. We provide both binary packages and Docker images, and you can deploy them in any way.
2.1 - Docker Compose
Image Download
Image repository: https://hub.docker.com/r/huatuo/huatuo-bamai/tags
Start a container with Docker
$ docker run --privileged --cgroupns=host --network=host -v /sys:/sys -v /proc:/proc -v /run:/run huatuo/huatuo-bamai:latest
⚠️ When this method is used, the container relies on the built-in default configuration file. That configuration does not connect to the kubelet or Elasticsearch.
Start containers with Docker Compose
Docker Compose allows you to quickly set up a complete local environment where you manage the collector, Elasticsearch, Prometheus, Grafana, and other components yourself.
$ docker compose --project-directory ./build/docker up
For Docker Compose installation instructions, see https://docs.docker.com/compose/install/linux/.
2.2 - Kubernetes Daemonset
This document describes how to deploy the Huatuo collector to a cloud-native cluster using a Kubernetes DaemonSet.
1. Download the configuration file
$ curl -L -o huatuo-bamai.conf https://github.com/ccfos/huatuo/raw/main/huatuo-bamai.conf
2. Modify the configuration file
Modify the configuration file according to your actual deployment environment. For example, adjust settings such as the storage backend and the method for obtaining Pod information. For details, see the Configuration Guide.
3. Create a ConfigMap
$ kubectl delete configmap huatuo-bamai-config
$ kubectl create configmap huatuo-bamai-config --from-file=./huatuo-bamai.conf
3. Deploy the Collector
$ kubectl apply -f https://github.com/ccfos/huatuo/blob/main/build/huatuo-daemonset.minimal.yaml
Notes:
- In
huatuo-daemonset.minimal.yaml, the container image uses thehuatuo-bamai:latesttag by default. For production deployments, replace it with a specific release version image. - When using
huatuo-bamai:latestfor testing, verify that the tag points to the latest image. You can remove the old image and pull it again by runningdocker image rm huatuo/huatuo-bamai:latest.
2.3 - Systemd Bare-Metal
The RPM release of HUATUO is available from the OpenCloudOS repository. Only version 2.1.0 is currently supported.
1. Download the RPM package
The OpenCloudOS mirror provides the HUATUO RPM package. Download the appropriate package for your architecture:
wget https://mirrors.opencloudos.tech/epol/9/Everything/x86_64/os/Packages/huatuo-bamai-2.1.0-2.oc9.x86_64.rpm
wget https://mirrors.opencloudos.tech/epol/9/Everything/aarch64/os/Packages/huatuo-bamai-2.1.0-2.oc9.aarch64.rpm
2. Install the RPM package
sudo rpm -ivh huatuo-bamai*.rpm
3. Modify the configuration
Edit the configuration file /etc/huatuo-bamai/huatuo-bamai.conf to match your deployment environment. For detailed configuration options, refer to the Configuration Guide.
4. Start the HUATUO service
sudo systemctl start huatuo-bamai
sudo systemctl enable huatuo-bamai
For complete installation instructions, see https://mp.weixin.qq.com/s/Gmst4_FsbXUIhuJw1BXNnQ
3 - Building from Source
1. Container Build
Run the following command to build the project and run static code checks.
$ sh build/build-run-testing-image.sh
Or run each step separately:
1. Prepare the build environment
$ docker build --network host -t huatuo/huatuo-bamai-dev:latest -f ./Dockerfile.devel .
2. Start the build container
$ docker run -it --privileged --cgroupns=host --network=host -v $(pwd):/go/huatuo-bamai huatuo/huatuo-bamai-dev:latest sh
3. Build inside the container
$ make
2. Publishing the Image
Use docker build to publish the latest binary container image.
docker build --network host -t huatuo/huatuo-bamai:latest .
3. Bare-Metal Build
3.1 Install Dependencies
Ubuntu 24.04:
apt install make git clang libbpf-dev linux-tools-common curl capnproto
Fedora 40:
dnf install make git clang libbpf-devel bpftool curl capnproto capnproto-devel glibc-static
go install mvdan.cc/gofumpt@v0.8.0
go install mvdan.cc/sh/v3/cmd/shfmt@v3.11.0
go install golang.org/x/tools/cmd/goimports@v0.36.0
go install github.com/golangci/golangci-lint/cmd/golangci-lint@v1.62.2
go install github.com/vektra/mockery/v2@v2.53.6
go install capnproto.org/go/capnp/v3/capnpc-go@v3.1.0-alpha.2
3.2 Build
$ make
4. BPF Debug Build
BPF code can use the bpf_dbg() and bpf_dbg_msg() macros (defined in bpf/include/bpf_dbg.h) to print debug information from kernel space. This helps you trace the runtime logic of eBPF programs. The feature uses a two-stage switch. It is fully disabled by default and adds no overhead to the production path.
4.1 Adding Trace Points in BPF Code
#include "bpf_dbg.h"
// Declare a debug map in each .c file that contains a BPF program to trace
// (the map name must match the name used below).
BPF_DBG_MAP(native_cpu);
SEC("perf_event")
int prog(void *ctx)
{
// Print a message only
bpf_dbg_msg(ctx, native_cpu, "enter prog");
// Print a message with up to 3 u64 arguments
bpf_dbg(ctx, native_cpu, "pid and addr", pid, addr, 0);
return 0;
}
When BPF_DEBUG=0 (the default), these macros expand to no-ops. The debug perf event array, the on-stack event struct, bpf_ktime_get_ns, and bpf_perf_event_output are not emitted. The verifier never sees them, the .o file is smaller, and no extra file descriptor is consumed at load time.
4.2 Enabling at Build Time (Stage 1: DEBUG_BPF)
Set BPF_DEBUG=1 to pass -DDEBUG_BPF to clang and compile the debug code into the BPF object:
$ make BPF_DEBUG=1 # Or build only the BPF objects: make BPF_DEBUG=1 bpf-build
4.3 Enabling at Runtime (Stage 2: log-bpf-debug)
Even when compiled into the object, debug output is still suppressed at runtime by default. To turn it on, pass --log-bpf-debug when you start the profiler (currently effective for the native profiler only):
$ ./profiler --type cpu --language native --log-bpf-debug ...
This works as follows: when the BPF object is loaded, a BpfDbg instance created by bpf.NewDbg(true) rewrites the bpf_dbg_enabled constant to 1 before LoadBpf. Without this rewrite, the verifier eliminates if (bpf_dbg_enabled) as dead code. Each BPF object holds its own BpfDbg, so the debug switches are independent of one another.
4.4 Output
Debug events are printed by user space as Debug-level logs. Each entry contains:
file: the BPF source file name where the trace point fired (__FILE_NAME__)line: the source line numberts: the event timestamp (bpf_ktime_get_nsconverted to UTC wall-clock time)msg: the message string passed to the trace pointargs: optional, up to 3u64arguments (omitted when all are 0)
Example:
bpf_dbg: file=native_cpu_profiler.c line=120 ts=2026-01-11T08:30:00.123456Z msg=enter prog args=[0x1f4 0xffff8881 0x0 0x0]
Note: Compile with
BPF_DEBUG=1and run with--log-bpf-debug.
4 - Configuration Guide
1. Overview
huatuo-bamai is the core collector of HUATUO (a BPF-based metrics and anomaly inspector). Its configuration file defines the data collection scope, probe enablement strategy, metric output format, anomaly detection rules, and logging behavior.
The configuration file uses TOML format and includes multiple sections such as global blacklist, logging, runtime resource limits, storage configuration, and AutoTracing. Each configuration item comes with detailed comments explaining its purpose, default value, and important notes. This document provides a clear and detailed English explanation for every configuration item to help users understand and safely customize the settings.
Note: Most parameters are provided as commented defaults (prefixed with #). Uncomment and adjust as needed. Changes take effect after restarting huatuo-bamai. In production, avoid enabling high-overhead features unnecessarily.
2. Global Blacklist
# Global blacklist for tracing and metrics
BlackList = ["netdev_hw", "metax_gpu"]
-
BlackList: Global blacklist for tracing and metrics.
Modules or hardware to exclude from tracing and metric collection. Default:
["netdev_hw", "metax_gpu"], which disables tracing and metrics for the network device hardware layer and Metax GPU. Supports arrays, extend as needed.
3. Logging
# Log Configuration
#
# - Level
# Log level: Debug, Info, Warn, Error, Panic.
# Default: Info
#
# - File
# Log file path. If empty, logs go to stdout.
# Default: empty
#
[Log]
# Level = "Info"
# File = ""
-
Level: Log verbosity. Values: Debug, Info, Warn, Error, Panic. Default: Info. Use Info or Warn in production; Debug for troubleshooting.
-
File: Log file path.
Specifies the path to the log file. If left empty, logs are not written to any file (output goes to stdout or system logs).
Default: empty.
Description: In containerized deployments, configure a specific path and integrate with a log collection system for persistence.
4. Runtime Resource Limits
# Runtime resource limit
#
# - LimitInitCPU
# During the huatuo-bamai startup, the CPU of process are restricted from use.
# Default is 0.5 CPU.
#
# - LimitCPU
# CPU limit at runtime.
# Default is 2.0 CPU.
#
# - LimitMem
# Memory limit in MB.
# Default is 2048MB.
#
[RuntimeCgroup]
# LimitInitCPU = 0.5
# LimitCPU = 2.0
# LimitMem = 2048
-
LimitInitCPU: CPU limit during startup phase.
Restricts CPU cores usable by the huatuo-bamai process during initialization.
Default: 0.5 CPU.
Description: Prevents excessive CPU usage during startup from affecting host business workloads. Value is in CPU cores (supports decimals).
-
LimitCPU: Runtime CPU limit.
Restricts CPU resources after the process has started.
Default: 2.0 CPU.
Description: Adjust based on node scale and workload. In high-density container environments, lower this value appropriately to ensure business stability.
-
LimitMem: Memory resource limit.
Maximum memory allowed for the huatuo-bamai process.
Default: 2048 MB.
Description: Enforced via cgroup to prevent OOM (Out Of Memory) issues. In production, increase as needed according to collection scale.
5. Storage
5.1 Elasticsearch and OpenSearch Storage
# Storage configuration
[Storage]
# Elasticsearch and OpenSearch Storage
#
# Disable ES/OS storage if one of Address, Username, Password is empty.
# Store the tracing and events data of linux kernel to ES/OS.
#
# - Address
# Default address is :9200 of localhost. Port 9200 is used for all API calls
# over HTTP. This includes search and aggregations, monitoring and anything
# else that uses a HTTP or HTTPS request. All client libraries will use this port to
# talk to Elasticsearch or OpenSearch.
# e.g.
# http://127.0.0.1:9200
# https://127.0.0.1:9200
#
# Default: :9200
#
# - Index
# Elasticsearch or OpenSearch index, a logical namespace that holds a collection of
# documents for huatuo-bamai.
# Default: huatuo_bamai
#
# - Username
# - Password
# There is no default username and password.
#
[Storage.ES]
# Address = "http://127.0.0.1:9200"
# Index = "huatuo_bamai"
Username = "elastic"
Password = "huatuo-bamai"
-
Address: ElasticSearch/OpenSearch service address.
Default: http://127.0.0.1:9200.
Description: Used to store kernel tracing and event data. ES/OS storage is disabled if any of Address, Username, or Password is empty. Port 9200 is the standard HTTP/HTTPS API port for ElasticSearch/OpenSearch.
-
Index: Index name.
Default: huatuo_bamai.
Description: Logical namespace for organizing huatuo-bamai tracing and event documents.
-
Username: Authentication username.
No default value (example uses elastic).
Description: Used for Basic Auth.
-
Password: Authentication password.
No default value (example uses huatuo-bamai).
Description: Used together with the username. In production, use a strong password and enable TLS encryption.
Overall: ES/OS storage persists kernel tracing and event data for later search and analysis.
5.2 Local File Storage
# LocalFile Storage
#
# Store data to local directory for troubleshooting on the host machine.
#
# - Path
# The directory for storing data. If the Path is empty, LocalFile will be disabled.
# Default: "huatuo-local"
#
# - RotationSize
# The maximum size in Megabytes of a record file before it gets rotated
# per kernel tracer.
# Default: 100MB
#
# - MaxRotation
# The maximum number of old log files to retain for per tracer.
# Default: 10
#
[Storage.LocalFile]
# Path = "huatuo-local"
# RotationSize = 100
# MaxRotation = 10
-
Path: Local data storage directory.
Default: huatuo-local. If empty, local file storage is disabled.
Description: Stores data locally on the host for on-site troubleshooting. Use an absolute path.
-
RotationSize: Single file rotation size.
Maximum size of a record file before rotation (per tracer).
Default: 100 MB.
Description: Prevents any single file from growing too large and consuming excessive disk space.
-
MaxRotation: Maximum number of rotated files to retain.
Default: 10.
Description: Oldest files are automatically deleted once the limit is reached, controlling disk usage.
6. Automatic Tracing
The automatic tracing module is one of HUATUO’s intelligent features. It triggers specific performance tracing based on thresholds, reducing manual intervention.
6.1 CPUIdle Automatic Tracing — Sudden High CPU Usage in Containers
# Autotracing configuration
[AutoTracing]
# cpuidle
#
# For sudden high CPU usage in containers.
#
# - UserThreshold
# User CPU usage threshold, when cpu usage reaches this threshold, cpu
# performance tracing will be triggered.
# Default: 75%
#
# - SysThreshold
# System CPU usage threshold, when reaching this threshold, cpu performance
# tracing will be triggered.
# Default: 45%
#
# - UsageThreshold
# The total cpu usage (system + user cpu usage) threshold, when reaching
# this threshold, cpu performance tracing will be triggered.
# Default: 45%
#
# - DeltaUserThreshold
# The range of this user cpu changes within a short period of time.
# Default: 45%
#
# - DeltaSysThreshold
# The range of this system cpu changes within a short period of time.
# Default: 20%
#
# - DeltaUsageThreshold
# The range of this cpu usage changes within a short period of time.
# Default: 55%
#
# - Interval
# The sample interval of the cpu usage for all containers.
# Default: 10s
#
# - IntervalTracing
# Time since last run. Avoid frequently executing this tracing to prevent
# performance impact.
# Default: 1800s
#
# - RunTracingToolTimeout
# Execution timeout of this tracing tool (seconds).
# Default: 10s
#
# NOTE:
# Profiling triggers when:
# 1. UserThreshold AND DeltaUserThreshold are exceeded, or
# 2. SysThreshold AND DeltaSysThreshold are exceeded, or
# 3. UsageThreshold AND DeltaUsageThreshold are exceeded
#
[AutoTracing.CPUIdle]
# UserThreshold = 75
# SysThreshold = 45
# UsageThreshold = 90
# DeltaUserThreshold = 45
# DeltaSysThreshold = 20
# DeltaUsageThreshold = 55
# Interval = 10
# IntervalTracing = 1800
# RunTracingToolTimeout = 10
-
UserThreshold: User-mode CPU usage threshold (%).
Default: 75%.
-
SysThreshold: System-mode CPU usage threshold (%).
Default: 45%.
-
UsageThreshold: Total CPU usage threshold (%).
Default: 90% (as shown in comments).
-
DeltaUserThreshold: Short-term user CPU change threshold (%).
Default: 45%.
-
DeltaSysThreshold: Short-term system CPU change threshold (%).
Default: 20%.
-
DeltaUsageThreshold: Short-term total CPU change threshold (%).
Default: 55%.
-
Interval: CPU usage sampling interval (seconds).
Default: 10s.
-
IntervalTracing: Minimum interval between runs (seconds).
Default: 1800s (30 minutes).
-
RunTracingToolTimeout: Single tracing execution timeout (seconds).
Default: 10s.
Trigger Logic: Tracing runs when any of the following is true:
- Both UserThreshold and DeltaUserThreshold are met, or
- Both SysThreshold and DeltaSysThreshold are met, or
- Both UsageThreshold and DeltaUsageThreshold are met.
Filter Container Filtering: Use Included/Excluded rule arrays to control monitoring scope.
# Each rule contains Field (filter field) and Pattern (regex).
# Field: container_host_namespace | container_hostname | container_qos
#
# [[AutoTracing.CPUIdle.Filter.Excluded]]
# Field = "container_qos"
# Pattern = "besteffort"
# [[AutoTracing.CPUIdle.Filter.Included]]
# Field = "container_host_namespace"
# Pattern = "^application-"
-
Filter: Container filtering rules. Defined using
[[double-bracket]]syntax with multiple rules, each containingField(filter field) andPattern(regex). Filtering logic:- No rules: monitor all containers
Excludedonly: blacklist, skip matched containersIncludedonly: whitelist, only monitor matched containers- Both: must match Included AND not match Excluded
Default: no rules, all containers monitored.
6.2 CPUSys Automatic Tracing — Sudden High System CPU on Host
# cpusys
#
# For sudden high system cpu usage on the host machine.
#
# - SysThreshold
# System CPU usage threshold, when reaching this threshold, cpu performance
# tracing will be triggered.
# Default: 45%
#
# - DeltaSysThreshold
# The range of system cpu changes within a short period of time.
# Default: 20%
#
# - Interval
# The sample interval of the cpu usage for host machine.
# Default: 10s
#
# - RunTracingToolTimeout
# Execution timeout of this tracing tool (seconds).
# Default: 10s
#
# NOTE:
# Profiling triggers when:
# SysThreshold AND DeltaSysThreshold are exceeded.
#
[AutoTracing.CPUSys]
# SysThreshold = 45
# DeltaSysThreshold = 20
# Interval = 10
# RunTracingToolTimeout = 10
-
SysThreshold: System CPU usage threshold (%).
Default: 45%.
-
DeltaSysThreshold: Short-term system CPU change threshold (%).
Default: 20%.
-
Interval: Host CPU usage sampling interval (seconds).
Default: 10s.
-
RunTracingToolTimeout: Tracing execution timeout (seconds).
Default: 10s.
Trigger Logic: Tracing is triggered when both SysThreshold and DeltaSysThreshold are satisfied.
6.3 Dload AutoTracing — D-State Task Profiling for Containers
# dload
#
# linux tasks D state profiling for containers.
#
# - ThresholdLoad
# Load average threshold. When exceeded, D-state profiling triggers.
# Default: 5
#
# - Interval
# The sample interval of the load for all containers.
# Default: 10s
#
# - IntervalTracing
# Time since last run. Avoid frequently executing this tracing to prevent
# performance impact.
# Default: 1800s
#
[AutoTracing.Dload]
# ThresholdLoad = 5
# Interval = 10
# IntervalTracing = 1800
-
ThresholdLoad: System load average (loadavg) threshold for containers.
Default: 5. Triggers D-state (uninterruptible sleep) task profiling when loadavg reaches this value.
-
Interval: Monitoring interval.
Default: 10s.
-
IntervalTracing: Minimum time between consecutive tracings.
Default: 1800s (30 minutes).
6.4 IOTracing AutoTracing — Container IO Performance Profiling
# iotracing
#
# io profiling for containers.
#
# - WbpsThreshold
# Max write bytes per second threshold. When exceeded, iotracing is triggered.
# For NVMe devices, UtilThreshold must also be met.
# Default: 1500 MB/s
#
# - RbpsThreshold
# Max read bytes per second threshold. When exceeded, iotracing is triggered.
# For NVMe devices, UtilThreshold must also be met.
# Default: 2000 MB/s
#
# - UtilThreshold
# Disk utilization (%). Consistently above 80-90% indicates a bottleneck.
# Default: 90%
#
# - AwaitThreshold
# Await (Average IO wait time in ms): High values indicate slow disk response times.
# Default: 100ms
#
# - RunTracingToolTimeout
# Execution timeout of this tracing tool (seconds).
# Default: 10s
#
# - MaxProcDump
# The number of processes displayed by iotracing tool.
# Default: 10
#
# - MaxFilesPerProcDump
# The number of files per process displayed by iotracing tool.
# Default: 5
#
[AutoTracing.IOTracing]
# WbpsThreshold = 1500
# RbpsThreshold = 2000
# UtilThreshold = 90
# AwaitThreshold = 100
# RunTracingToolTimeout = 10
# MaxProcDump = 10
# MaxFilesPerProcDump = 5
-
WbpsThreshold: Max write bytes per second threshold (MB/s).
Default: 1500. (For NVMe, must also meet UtilThreshold.)
-
RbpsThreshold: Max read bytes per second threshold (MB/s).
Default: 2000.
-
UtilThreshold: Disk utilization threshold (%).
Default: 90%.
-
AwaitThreshold: Average IO wait time threshold (ms).
Default: 100ms.
-
RunIOTracingTimeout: IO tracing tool timeout (seconds).
Default: 10s.
-
MaxProcDump: Maximum number of processes to display.
Default: 10.
-
MaxFilesPerProcDump: Maximum files per process to display.
Default: 5.
Description: Used for diagnosing IO hotspots in containers, especially under high disk load.
6.5 MemoryBurst AutoTracing
This module detects sudden memory usage spikes on the host and automatically captures kernel context to help diagnose memory pressure events.
# memory burst
#
# Capture kernel context on sudden host memory usage spikes.
#
# - Interval
# Memory usage sampling interval (seconds).
# Default: 10s
#
# - DeltaMemoryBurst
# Growth percentage threshold for memory usage. 100% means, e.g.,
# memory usage increased from 200MB to 400MB.
# Default: 100%
#
# - DeltaAnonThreshold
# Growth percentage threshold for anonymous memory. 100% means, e.g.,
# anon memory increased from 200MB to 400MB.
# Default: 70%
#
# - IntervalTracing
# Time since last run. Avoid frequently executing this tracing
# to prevent performance impact.
# Default: 1800s
#
# - DumpProcessMaxNum
# Number of processes to dump when triggered.
# Default: 10
#
[AutoTracing.MemoryBurst]
# DeltaMemoryBurst = 100
# DeltaAnonThreshold = 70
# Interval = 10
# IntervalTracing = 1800
# SlidingWindowLength = 60
# DumpProcessMaxNum = 10
-
DeltaMemoryBurst: Memory usage burst growth percentage threshold.
Default: 100%.
-
DeltaAnonThreshold: Anonymous memory burst growth percentage threshold.
Default: 70%.
-
Interval: Memory usage sampling interval (seconds).
Default: 10s.
-
IntervalTracing: Minimum interval between runs (seconds).
Default: 1800s.
-
SlidingWindowLength: Sliding window length (seconds).
Default: 60s.
-
DumpProcessMaxNum: Maximum processes to dump on trigger.
Default: 10.
6.6 Known Issue Filtering (IssuesList)
# IssuesList for known issue filtering in autotracing
IssuesList = []
-
IssuesList: Known issue filter. Format:
[["name", "regex"], ...]. When a collected stack trace matches the regex, it is labeled with the issue name. Default[].Example:
IssuesList = [["known_issue1", "softlockup"], ["known_issue2", "alloc_pages.*failed"]]
Note: Only supports dload tracing of known issues filtering, other events are not supported.
7. Event Tracing
This section is responsible for capturing key kernel events and monitoring latency, including softirq, memory reclaim, network receive latency, network device events, and packet drop monitoring. It is the core module for kernel-level anomaly context collection in HUATUO.
7.1 Softirq Disable Tracing
# linux kernel events capturing configuration
[EventTracing]
# softirq
#
# Trace softirq disabled events in the Linux kernel.
#
# - DisabledThreshold
# When the disable duration of softirq exceeds the threshold, huatuo-bamai
# will collect kernel context.
# Default: 10000000 in nanoseconds, 10ms
#
[EventTracing.Softirq]
# DisabledThreshold = 10000000
-
DisabledThreshold: Softirq disable duration threshold (nanoseconds).
Default: 10,000,000 ns (10ms). When softirq is disabled longer than this threshold, kernel context is collected.
Description: Long softirq disable periods can cause delays in networking, timers, etc. Useful for diagnosing interrupt storms or high-load scenarios.
7.2 Memory Reclaim Blocking Tracing
# memreclaim
#
# The memory reclaim may block the process, if one process is blocked
# for a long time, reporting the events to userspace.
#
# - BlockedThreshold
# The blocked time when memory reclaiming.
# Default: 900000000ns, 900ms
#
[EventTracing.MemoryReclaim]
# BlockedThreshold = 900000000
-
BlockedThreshold: Memory reclaim blocking time threshold (nanoseconds).
Default: 900,000,000 ns (900ms). When a process is blocked by memory reclaim for longer than this time, an event is reported to userspace with context.
Description: Memory reclaim blocking is a common cause of process stalls, especially in memory-constrained cloud-native environments.
7.3 Network Receive Latency Tracing
# networking rx latency
#
# linux net stack rx latency for every tcp skbs.
#
# - Driver2NetRx
# The latency from driver to net rx, e.g., netif_receive_skb.
# Default: 5ms
#
# - Driver2TCP
# The latency from driver to tcp rx, e.g., tcp_v4_rcv.
# Default: 10ms
#
# - Driver2Userspace
# The latency from driver to userspace copy data, e.g., skb_copy_datagram_iovec.
# Default: 115ms
#
# - ExcludedContainerQos
# Blacklist: skip containers whose qos level matches.
# Values: "guaranteed", "burstable", "besteffort" (case-insensitive).
# Default: [].
#
# - ExcludedHostNetnamespace
# Exclude packets in the host network namespace.
# Default: true
#
[EventTracing.NetRxLatency]
# Driver2NetRx = 5
# Driver2TCP = 10
# Driver2Userspace = 115
# ExcludedContainerQos = []
ExcludedContainerQos = ["besteffort"]
# ExcludedHostNetnamespace = true
-
Driver2NetRx: Latency threshold from driver to network receive layer (e.g., netif_receive_skb).
Default: 5ms.
-
Driver2TCP: Latency threshold from driver to TCP receive (e.g., tcp_v4_rcv).
Default: 10ms.
-
Driver2Userspace: Latency threshold from driver to userspace data copy (e.g., skb_copy_datagram_iovec).
Default: 115ms.
-
ExcludedContainerQos: Container QoS levels to exclude (blacklist).
Default: []. Corresponds to Kubernetes Pod QoS levels (Guaranteed, Burstable, BestEffort).
-
ExcludedHostNetnamespace: Whether to exclude packets in the host network namespace.
Default: true.
7.4 Network Device Event Monitoring
# netdev events
#
# Monitor network device events.
#
# - DeviceList
# The net devices we monitor.
# Default: [] (empty, meaning no devices).
#
[EventTracing.Netdev]
DeviceList = ["eth0", "eth1", "bond4", "lo"]
-
DeviceList: List of network device full-match regex patterns to monitor. Literal names such as
"eth0"keep exact-match behavior; patterns such as"bond[0-9]+"can select multiple devices.Default example includes “eth0”, “eth1”, “bond4”, “lo”. An empty list means no devices are monitored.
Description: Monitors physical link status events for specified network interfaces.
7.5 Packet Drop Monitoring
# dropwatch
#
# monitor packets dropped events in the Linux kernel.
#
# - ExcludedNeighInvalidate
# Exclude neigh_invalidate drop events.
# Default: true
#
[EventTracing.Dropwatch]
# ExcludedNeighInvalidate = true
-
ExcludedNeighInvalidate: Whether to exclude packet drops caused by neigh_invalidate.
Default: true.
Description: Neighbor table related drops are usually normal behavior; excluding them reduces false positives.
7.6 Hardware Error Event Tracing (EventTracing.Ras)
# ras
#
# Hardware error event tracing (RAS: Reliability, Availability, Serviceability).
# Captures MCE, EDAC, ACPI/GHES, PCIe AER, and MCE threshold (THR) events via eBPF.
#
# - MceThrBackoff
# Minimum interval in seconds between consecutive MCE threshold (THR) event saves.
# THR events are fired by the local-APIC threshold interrupt and can storm at high
# frequency; this cooldown prevents flooding storage with redundant records.
# Default: 1800s (30 minutes)
#
[EventTracing.Ras]
# MceThrBackoff = 1800
-
MceThrBackoff: Minimum cooldown in seconds between MCE threshold (THR) event saves.
Default: 1800s (30 minutes).
Description: THR events are generated by the CPU’s local-APIC threshold interrupt when correctable hardware errors accumulate. These can fire at very high frequency during hardware degradation. The backoff suppresses redundant saves while ensuring at least one record is captured per interval. Lower values provide more granular event records at the cost of higher storage throughput; in environments with frequent correctable errors, consider raising this value to reduce noise.
7.8 Known Issue Filtering (IssuesList)
# IssuesList for known issue filtering in event tracing
IssuesList = []
-
IssuesList: Known issue filter. Same format and usage as AutoTracing
IssuesList. Matches event titles against regex patterns, labeling them with the issue name. Default[].Example:
IssuesList = [["known_issue1", "comm=ignored_process"]]
Note: Only supports net_rx_latency tracing of known issues filtering, other events are not supported.
8. Metric Collector
This section defines collection rules for various system and network metrics. All Included/Excluded fields share the same filter logic (regex):
- No rules: all items are collected
- Excluded only: blacklist, matched items are skipped
- Included only: whitelist, only matched items are collected
- Both: must match Included AND not match Excluded
8.1 Netdev Statistics
# Metric Collector
[MetricCollector]
# Netdev statistic
#
# - EnableNetlink
# Use netlink instead of procfs net/dev to get netdev statistic.
# Only support the host environment to use `netlink` now.
# Default is "false".
#
# - DeviceIncluded
# Accept special devices in netdev statistic.
# Default: "" (empty), meaning include all.
#
# - DeviceExcluded
# Exclude special devices in netdev statistic.
# Default: "" (empty), meaning exclude nothing.
#
# Filter logic see MetricCollector section header.
#
[MetricCollector.NetdevStats]
# EnableNetlink = false
# DeviceIncluded = ""
DeviceExcluded = "^(lo)|(docker\\w*)|(veth\\w*)$"
-
EnableNetlink: Use netlink instead of procfs to collect netdev statistics.
Default: false. Currently only supported on the host.
-
DeviceIncluded: Regex to include specific devices. Default: include all.
-
DeviceExcluded: Regex to exclude devices. Example: “^(lo)|(docker\w*)|(veth\w*)$”, meaning exclude loopback, docker, and veth interfaces.
8.2 Netdev DCB Collection
# netdev dcb, DCB (Data Center Bridging)
#
# Collecting the DCB PFC (Priority-based Flow Control).
#
# - DeviceList
# The net devices we monitor.
# Default: [] (empty, meaning no devices).
#
[MetricCollector.NetdevDCB]
DeviceList = ["eth0", "eth1"]
-
DeviceList: List of network device full-match regex patterns for which DCB (Data Center Bridging) PFC information is collected.
Default: empty.
8.3 Netdev Hardware Statistics
# netdev hardware statistic
#
# Collecting the hardware statistic of net devices, e.g, rx_dropped.
#
# - DeviceList
# The net devices we monitor.
# Default: [] (empty, meaning no devices).
#
[MetricCollector.NetdevHW]
DeviceList = ["eth0", "eth1"]
-
DeviceList: List of network device full-match regex patterns for hardware-level statistics (e.g., rx_dropped).
Default: empty.
8.4 Qdisc Collection
# Qdisc
#
# - DeviceIncluded / DeviceExcluded
# Same as above.
#
[MetricCollector.Qdisc]
# DeviceIncluded = ""
DeviceExcluded = "^(lo)|(docker\\w*)|(veth\\w*)$"
- DeviceIncluded / DeviceExcluded: Same as above.
8.5 vmstat Metric Collection
# vmstat
#
# This metric supports host vmstat and cgroup vmstat.
# - IncludedOnHost / ExcludedOnHost: same as above, for host /proc/vmstat.
# - IncludedOnContainer / ExcludedOnContainer: same, for cgroup containers memory.stat.
#
[MetricCollector.Vmstat]
IncludedOnHost = "allocstall|nr_active_anon|nr_active_file|nr_boost_pages|nr_dirty|nr_free_pages|nr_inactive_anon|nr_inactive_file|nr_kswapd_boost|nr_mlock|nr_shmem|nr_slab_reclaimable|nr_slab_unreclaimable|nr_unevictable|nr_writeback|numa_pages_migrated|pgdeactivate|pgrefill|pgscan_direct|pgscan_kswapd|pgsteal_direct|pgsteal_kswapd"
ExcludedOnHost = "total"
IncludedOnContainer = "active_anon|active_file|dirty|inactive_anon|inactive_file|pgdeactivate|pgrefill|pgscan_direct|pgscan_kswapd|pgsteal_direct|pgsteal_kswapd|shmem|unevictable|writeback|pgscan_globaldirect|pgscan_globalkswapd|pgscan_cswapd|pgsteal_cswapd|pgsteal_globaldirect|pgsteal_globalkswapd"
ExcludedOnContainer = "total"
-
IncludedOnHost / ExcludedOnHost: Filter fields for host /proc/vmstat.
-
IncludedOnContainer / ExcludedOnContainer: Filter fields for container cgroup memory.stat.
8.6 Other Metric Collections
# MemoryEvents/Netstat/MountPointStat
#
# - Included / Excluded: same as above.
# - MountPointsIncluded: whitelist only (no Excluded), same logic.
#
[MetricCollector.MemoryEvents]
Included = "watermark_inc|watermark_dec"
# Excluded = ""
[MetricCollector.Netstat]
# Excluded = ""
# Included = ""
# MountPointStat
[MetricCollector.MountPointStat]
MountPointsIncluded = "(^/home$)|(^/$)|(^/boot$)"
-
Included / Excluded: Same as above.
-
MountPointsIncluded: Regex for mount points to collect. Default includes /, /home, /boot.
9. Pod
This section configures how to fetch Pod information from kubelet to enable container/Pod-level labeling and metric isolation.
# Pod Configuration
#
# Configure these parameters for fetching pods from kubelet.
#
# - KubeletReadOnlyPort
# The KubeletReadOnlyPort is kubelet read-only port for the Kubelet to serve on with
# no authentication/authorization. The port number must be between 1 and 65535, inclusive.
# Setting this field to 0 disables fetching pods from kubelet read-only service.
# Default: 10255
#
# - KubeletAuthorizedPort
# The port is the HTTPs port of the kubelet. The port number must be between 1 and 65535,
# inclusive. Setting this field to 0 disables fetching pods from kubelet HTTPS port.
# Default: 10250
#
# - KubeletClientCertPath
# https://kubernetes.io/docs/setup/best-practices/certificates/
#
# Client certificate and private key file name. One file or two files:
# "/path/to/xxx-kubelet-client.crt,/path/to/xxx-kubelet-client.key",
# "/path/to/kubelet-client-current.pem"
#
# You can disable this kubelet fetching pods, for bare metal service, by
# KubeletReadOnlyPort = 0, and KubeletAuthorizedPort = 0.
#
[Pod]
KubeletClientCertPath = "/etc/kubernetes/pki/apiserver-kubelet-client.crt,/etc/kubernetes/pki/apiserver-kubelet-client.key"
-
KubeletReadOnlyPort: Kubelet read-only port.
Default: 10255. Set to 0 to disable this method.
-
KubeletAuthorizedPort: Kubelet HTTPS authorized port.
Default: 10250. Set to 0 to disable.
-
KubeletClientCertPath: Path to kubelet client certificate and private key. Supports comma-separated files or single PEM file.
Description: Used for mTLS authentication on the HTTPS port. In non-Kubernetes (bare-metal) environments, set both ports to 0 to disable Pod fetching.
10. Events Watch
This section controls the runtime behavior of the POST /v1/events/watch SSE streaming API, through which external clients can subscribe to a real-time stream of kernel events.
# Events Watch Configuration
#
# Controls the behavior of the POST /v1/events/watch SSE streaming API,
# which allows external clients to subscribe to kernel events in real-time.
#
# - MaxClients
# Maximum number of concurrent clients allowed to hold an open /v1/events/watch
# connection. Once the limit is reached, new requests are rejected with HTTP 429
# (Too Many Requests) until an existing client disconnects.
# Default: 100
#
# - KeepAliveInterval
# Interval in seconds at which the server sends an SSE comment ping to each
# connected client. The ping keeps the HTTP connection alive through load
# balancers and proxies that would otherwise time out idle connections.
# If writing the ping fails three consecutive times the server treats the
# client as gone and closes the connection.
# Default: 30s
#
[EventsWatch]
# MaxClients = 100
# KeepAliveInterval = 30
-
MaxClients: Maximum number of concurrent
/v1/events/watchconnections.Default: 100. When this limit is reached, new requests are rejected with HTTP 429 (Too Many Requests) until an existing client disconnects.
Description: Tune this value based on available node resources and the expected number of subscribers. Each open connection occupies a goroutine and a buffered subscription channel (256 events deep); keep memory pressure in mind when setting a high value.
-
KeepAliveInterval: Interval in seconds between SSE heartbeat pings sent to each connected client.
Default: 30s. The server sends an SSE comment line (
": ping") at this interval to keep the HTTP long-polling connection alive through load balancers and proxies that would otherwise close idle connections.Description: If three consecutive write attempts (ping or event data) fail, the server considers the client gone and closes the connection, releasing all associated resources. Set this value below the idle-timeout of any upstream proxy. Common production values are 15–60s.
11. CLI Flags
huatuo-bamai supports the following command-line flags:
huatuo-bamai --region <region> [options]
| Flag | Description | Default |
|---|---|---|
--config |
Configuration file name | huatuo-bamai.conf |
--config-dir |
Configuration file directory | conf |
--bpf-dir |
BPF object file directory | bpf |
--tools-bin-dir |
Tracing tool binary directory | bin |
--region |
Deployment region (required) | - |
--disable-kubelet |
Disable kubelet Pod fetching | false |
--disable-storage |
Disable storage backends | false |
--disable-cgroup |
Disable self cgroup resource limits | false |
--disable-tracing |
Disable specified tracing modules (may be repeated) | - |
--log-debug |
Force log level to Debug | false |
--dry-run |
Load-only test; exit gracefully after startup | false |
--procfs-prefix |
procfs mount point prefix | - |
12. Configuration Override Precedence
When the same configuration item is set in both command-line flags and the configuration file, the following precedence applies:
CLI flag > Configuration file > Built-in default
Specific rules:
-
Log level:
--log-debug> config file[Log] Level> built-in defaultInfo--log-debughas the highest priority and forces the log level toDebugregardless of theLevelvalue in the configuration file.- An explicit
Levelin the configuration file overrides the built-in default. - If neither is set, the default
Infois used.
-
Tracing blacklist:
--disable-tracingis merged with the configuration fileBlackList(they complement each other rather than override). -
Other boolean switches (
--disable-kubelet,--disable-storage,--disable-cgroup): When explicitly set on the command line, they override the configuration file.
13. Best Practices and Important Notes
- Resource Control: In production, prioritize adjusting CPU and memory limits in [RuntimeCgroup] to avoid impacting business containers.
- Storage Choice: For small-scale deployments, prefer [Storage.LocalFile] for local troubleshooting. For large clusters, configure Elasticsearch for centralized storage and querying.
- AutoTracing Tuning: Adjust thresholds based on workload characteristics. Thresholds that are too low cause frequent triggering; thresholds that are too high may miss issues. Validate gradually in a test environment.
- Security: Use strong passwords for ES configuration and consider enabling HTTPS. Avoid hard-coding sensitive information in the configuration file.
- Compatibility: Configuration parameters may be affected by kernel version and hardware environment. Always verify with the official HUATUO documentation for your specific setup.
By properly configuring huatuo-bamai.conf, you can fully leverage HUATUO’s capabilities in kernel-level anomaly detection and intelligent tracing, significantly improving observability and troubleshooting efficiency in cloud-native systems.
If you need deeper customization for a specific scenario, feel free to provide more details about your environment.
5 - Key Feature
5.1 - Kernel-Wide Insight
Metrics supported in the current version:
CPU
Scheduling
The following metrics allow observation of process scheduling latency, i.e., the time from when a process becomes runnable (placed in the run queue) until it actually starts executing on the CPU.
# HELP huatuo_bamai_runqlat_container_latency cpu run queue latency for the containers
# TYPE huatuo_bamai_runqlat_container_latency gauge
huatuo_bamai_runqlat_container_latency{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev",zone="0"} 226
huatuo_bamai_runqlat_container_latency{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev",zone="1"} 0
huatuo_bamai_runqlat_container_latency{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev",zone="2"} 0
huatuo_bamai_runqlat_container_latency{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev",zone="3"} 0
# HELP huatuo_bamai_runqlat_latency cpu run queue latency for the host
# TYPE huatuo_bamai_runqlat_latency gauge
huatuo_bamai_runqlat_latency{host="hostname",region="dev",zone="0"} 35100
huatuo_bamai_runqlat_latency{host="hostname",region="dev",zone="1"} 0
huatuo_bamai_runqlat_latency{host="hostname",region="dev",zone="2"} 0
huatuo_bamai_runqlat_latency{host="hostname",region="dev",zone="3"} 0
| Metric | Description | Unit | Target | Source | Labels |
|---|---|---|---|---|---|
| runqlat_container_latency | scheduling latency histogram buckets: zone0: 0–10 ms zone1: 10–20 ms zone2: 20–50 ms zone3: 50+ ms |
count | Container | eBPF | container_host, container_hostnamespace, container_level, container_name, container_type, host, region, zone |
| runqlat_latency | scheduling latency histogram buckets: zone0, 0~10ms zone1, 10-20ms zone2, 20-50ms zone3, 50+ms |
count | Host | eBPF | host, region, zone |
SoftIRQ
SoftIRQ response latency on different CPUs (currently only NET_RX and NET_TX are collected).
# HELP huatuo_bamai_softirq_latency softirq latency
# TYPE huatuo_bamai_softirq_latency gauge
huatuo_bamai_softirq_latency{cpuid="0",host="hostname",region="dev",type="NET_RX",zone="0"} 125
huatuo_bamai_softirq_latency{cpuid="0",host="hostname",region="dev",type="NET_RX",zone="1"} 2
huatuo_bamai_softirq_latency{cpuid="0",host="hostname",region="dev",type="NET_RX",zone="2"} 0
huatuo_bamai_softirq_latency{cpuid="0",host="hostname",region="dev",type="NET_RX",zone="3"} 0
huatuo_bamai_softirq_latency{cpuid="0",host="hostname",region="dev",type="NET_TX",zone="0"} 0
huatuo_bamai_softirq_latency{cpuid="0",host="hostname",region="dev",type="NET_TX",zone="1"} 0
huatuo_bamai_softirq_latency{cpuid="0",host="hostname",region="dev",type="NET_TX",zone="2"} 0
huatuo_bamai_softirq_latency{cpuid="0",host="hostname",region="dev",type="NET_TX",zone="3"} 0
huatuo_bamai_softirq_latency{cpuid="1",host="hostname",region="dev",type="NET_RX",zone="0"} 110
huatuo_bamai_softirq_latency{cpuid="1",host="hostname",region="dev",type="NET_RX",zone="1"} 0
huatuo_bamai_softirq_latency{cpuid="1",host="hostname",region="dev",type="NET_RX",zone="2"} 1
huatuo_bamai_softirq_latency{cpuid="1",host="hostname",region="dev",type="NET_RX",zone="3"} 0
huatuo_bamai_softirq_latency{cpuid="1",host="hostname",region="dev",type="NET_TX",zone="0"} 0
huatuo_bamai_softirq_latency{cpuid="1",host="hostname",region="dev",type="NET_TX",zone="1"} 0
huatuo_bamai_softirq_latency{cpuid="1",host="hostname",region="dev",type="NET_TX",zone="2"} 0
| Metric | Description | Unit | Target | Source | Labels |
|---|---|---|---|---|---|
| softirq_latency | SoftIRQ response latency histogram buckets: zone0, 0-10us zone1, 10-100us zone2, 100-1000us zone3, 1+ms |
count | Host | eBPF | cpuid, host, region, type, zone |
Utilization
Metrics showing CPU usage on hosts and containers (Prometheus format):
# HELP huatuo_bamai_cpu_util_sys cpu sys for the host
# TYPE huatuo_bamai_cpu_util_sys gauge
huatuo_bamai_cpu_util_sys{host="hostname",region="dev"} 6.268857848549965e-06
# HELP huatuo_bamai_cpu_util_total cpu total for the host
# TYPE huatuo_bamai_cpu_util_total gauge
huatuo_bamai_cpu_util_total{host="hostname",region="dev"} 1.7736934944144352e-05
# HELP huatuo_bamai_cpu_util_usr cpu usr for the host
# TYPE huatuo_bamai_cpu_util_usr gauge
huatuo_bamai_cpu_util_usr{host="hostname",region="dev"} 1.1468077095594387e-05
# HELP huatuo_bamai_cpu_util_container_sys cpu sys for the containers
# TYPE huatuo_bamai_cpu_util_container_sys gauge
huatuo_bamai_cpu_util_container_sys{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 1.6708593420881415e-07
# HELP huatuo_bamai_cpu_util_container_total cpu total for the containers
# TYPE huatuo_bamai_cpu_util_container_total gauge
huatuo_bamai_cpu_util_container_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 3.379584661890774e-07
# HELP huatuo_bamai_cpu_util_container_usr cpu usr for the containers
# TYPE huatuo_bamai_cpu_util_container_usr gauge
huatuo_bamai_cpu_util_container_usr{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 1.7087253017325962e-07
| Metric | Description | Unit | Target | Labels |
|---|---|---|---|---|
| cpu_util_sys | CPU system (kernel) time % | % | Host | host, region |
| cpu_util_usr | CPU user time % | % | Host | host, region |
| cpu_util_total | CPU total utilization % | % | Host | host, region |
| cpu_util_container_sys | Container CPU system time % | % | Container | container_host,container_hostnamespace,container_level,container_name,container_type,host,region |
| cpu_util_container_usr | Container CPU user time % | % | Container | container_host,container_hostnamespace,container_level,container_name,container_type,host,region |
| cpu_util_container_total | Container CPU total % | % | Container | container_host,container_hostnamespace,container_level,container_name,container_type,host,region |
Allocation
Container CPU resource configuration:
# HELP huatuo_bamai_cpu_util_container_cores cpu core number for the containers
# TYPE huatuo_bamai_cpu_util_container_cores gauge
huatuo_bamai_cpu_util_container_cores{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="Burstable",container_name="coredns",container_type="Normal",host="hostname",region="dev"} 6
| Metric | Description | Unit | Target | Labels |
|---|---|---|---|---|
| cpu_util_container_cores | Number of CPU cores | cores | Container | (same as above) |
Contention
Metrics reflecting container throttling and contention:
# HELP huatuo_bamai_cpu_stat_container_nr_throttled throttle nr for the containers
# TYPE huatuo_bamai_cpu_stat_container_nr_throttled gauge
huatuo_bamai_cpu_stat_container_nr_throttled{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_cpu_stat_container_throttled_time throttle time for the containers
# TYPE huatuo_bamai_cpu_stat_container_throttled_time gauge
huatuo_bamai_cpu_stat_container_throttled_time{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
| Metric | Description | Unit | Target | Labels |
|---|---|---|---|---|
| cpu_stat_container_nr_throttled | Number of times the cgroup was throttled | count | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| cpu_stat_container_throttled_time | Total time the cgroup was throttled | nanoseconds | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
Ref:
- https://docs.kernel.org/scheduler/sched-bwc.html#statistics
- https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html#cpu-interface-files
Future metrics (Didi kernel extensions – not yet public):
# HELP huatuo_bamai_cpu_stat_container_wait_rate wait rate for the containers
# TYPE huatuo_bamai_cpu_stat_container_wait_rate gauge
huatuo_bamai_cpu_stat_container_wait_rate{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_cpu_stat_container_throttle_wait_rate throttle wait rate for the containers
# TYPE huatuo_bamai_cpu_stat_container_throttle_wait_rate gauge
huatuo_bamai_cpu_stat_container_throttle_wait_rate{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_cpu_stat_container_inner_wait_rate inner wait rate for the containers
# TYPE huatuo_bamai_cpu_stat_container_inner_wait_rate gauge
huatuo_bamai_cpu_stat_container_inner_wait_rate{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_cpu_stat_container_exter_wait_rate exter wait rate for the containers
# TYPE huatuo_bamai_cpu_stat_container_exter_wait_rate gauge
huatuo_bamai_cpu_stat_container_exter_wait_rate{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
Burst Behavior
Metrics showing burst usage beyond quota:
# HELP huatuo_bamai_cpu_stat_container_nr_bursts burst nr for the containers
# TYPE huatuo_bamai_cpu_stat_container_nr_bursts gauge
huatuo_bamai_cpu_stat_container_nr_bursts{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
huatuo_bamai_cpu_stat_container_nr_bursts{container_host="coredns-855c4dd65d-mnpqf",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_cpu_stat_container_burst_time burst time for the containers
# TYPE huatuo_bamai_cpu_stat_container_burst_time gauge
huatuo_bamai_cpu_stat_container_burst_time{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
huatuo_bamai_cpu_stat_container_burst_time{container_host="coredns-855c4dd65d-mnpqf",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
| Metric | Description | Unit | Target | Labels |
|---|---|---|---|---|
| cpu_stat_container_burst_time | Cumulative wall-clock time spent above quota across all periods | count | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| cpu_stat_container_nr_bursts | Number of periods in which usage exceeded quota | count | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
Load
Load average and runnable/uninterruptible task counts:
# HELP huatuo_bamai_loadavg_load1 system load average, 1 minute
# TYPE huatuo_bamai_loadavg_load1 gauge
huatuo_bamai_loadavg_load1{host="hostname",region="dev"} 0.3
# HELP huatuo_bamai_loadavg_load15 system load average, 15 minutes
# TYPE huatuo_bamai_loadavg_load15 gauge
huatuo_bamai_loadavg_load15{host="hostname",region="dev"} 0.22
# HELP huatuo_bamai_loadavg_load5 system load average, 5 minutes
# TYPE huatuo_bamai_loadavg_load5 gauge
huatuo_bamai_loadavg_load5{host="hostname",region="dev"} 0.2
# HELP huatuo_bamai_loadavg_container_nr_running nr_running of container
# TYPE huatuo_bamai_loadavg_container_nr_running gauge
huatuo_bamai_loadavg_container_nr_running{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 1
# HELP huatuo_bamai_loadavg_container_nr_uninterruptible nr_uninterruptible of container
# TYPE huatuo_bamai_loadavg_container_nr_uninterruptible gauge
huatuo_bamai_loadavg_container_nr_uninterruptible{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
| Metric | Description | Unit | Target | Labels | |
|---|---|---|---|---|---|
| loadavg_load1 | 1-minute system load average | count | Host | host, region | |
| loadavg_load5 | 5-minute system load average | count | Host | host, region | |
| loadavg_load15 | 15-minute system load average | count | Host | host, region | |
| loadavg_container_container_nr_running | Number of running tasks in container | count | Container | host, region | cgroup v1 only |
| loadavg_container_container_nr_uninterruptible | Number of uninterruptible tasks in container | count | Container | host, region | cgroup v1 only |
Memory System
Reclaim
Metrics showing time spent stalled due to memory reclaim/compaction:
# HELP huatuo_bamai_memory_free_allocpages_stall time stalled in alloc pages
# TYPE huatuo_bamai_memory_free_allocpages_stall gauge
huatuo_bamai_memory_free_allocpages_stall{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_free_compaction_stall time stalled in memory compaction
# TYPE huatuo_bamai_memory_free_compaction_stall gauge
huatuo_bamai_memory_free_compaction_stall{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_reclaim_container_directstall counter of cgroup reclaim when try_charge
# TYPE huatuo_bamai_memory_reclaim_container_directstall gauge
huatuo_bamai_memory_reclaim_container_directstall{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
| Metric | Description | Unit | Target | Source | Labels |
|---|---|---|---|---|---|
| memory_free_allocpages_stall | Time stalled waiting for page allocation | nanoseconds | Host | eBPF | host, region |
| memory_free_compaction_stall | Time stalled in memory compaction | nanoseconds | Host | eBPF | host, region |
| memory_reclaim_container_directstall | Number of direct reclaim events in container | count | Container | eBPF | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
Note: The
memory_others_container_directstall_time,memory_others_container_asyncreclaim_time, andmemory_others_container_local_direct_reclaim_timemetrics read memory cgroup extension interfaces provided by the Didi Cloud custom kernel (memory.directstall_stat,memory.asynreclaim_stat,memory.local_direct_reclaim_time). Mainline and common distribution kernels do not expose these interfaces, so these metrics are simply not emitted there — this is expected, and no extra kernel module can provide them. To observe container direct reclaim behavior on standard kernels, use the eBPF-basedmemory_reclaim_container_directstalllisted above.
State
From cgroup memory.stat:
# HELP huatuo_bamai_memory_vmstat_container_active_anon cgroup memory.stat active_anon
# TYPE huatuo_bamai_memory_vmstat_container_active_anon gauge
huatuo_bamai_memory_vmstat_container_active_anon{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 1.47456e+07
# HELP huatuo_bamai_memory_vmstat_container_active_file cgroup memory.stat active_file
# TYPE huatuo_bamai_memory_vmstat_container_active_file gauge
huatuo_bamai_memory_vmstat_container_active_file{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 2.3617536e+07
# HELP huatuo_bamai_memory_vmstat_container_file_dirty cgroup memory.stat file_dirty
# TYPE huatuo_bamai_memory_vmstat_container_file_dirty gauge
huatuo_bamai_memory_vmstat_container_file_dirty{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_container_file_writeback cgroup memory.stat file_writeback
# TYPE huatuo_bamai_memory_vmstat_container_file_writeback gauge
huatuo_bamai_memory_vmstat_container_file_writeback{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_container_inactive_anon cgroup memory.stat inactive_anon
# TYPE huatuo_bamai_memory_vmstat_container_inactive_anon gauge
huatuo_bamai_memory_vmstat_container_inactive_anon{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_container_inactive_file cgroup memory.stat inactive_file
# TYPE huatuo_bamai_memory_vmstat_container_inactive_file gauge
huatuo_bamai_memory_vmstat_container_inactive_file{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 65536
# HELP huatuo_bamai_memory_vmstat_container_pgdeactivate cgroup memory.stat pgdeactivate
# TYPE huatuo_bamai_memory_vmstat_container_pgdeactivate gauge
huatuo_bamai_memory_vmstat_container_pgdeactivate{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_container_pgrefill cgroup memory.stat pgrefill
# TYPE huatuo_bamai_memory_vmstat_container_pgrefill gauge
huatuo_bamai_memory_vmstat_container_pgrefill{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_container_pgscan_direct cgroup memory.stat pgscan_direct
# TYPE huatuo_bamai_memory_vmstat_container_pgscan_direct gauge
huatuo_bamai_memory_vmstat_container_pgscan_direct{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_container_pgscan_kswapd cgroup memory.stat pgscan_kswapd
# TYPE huatuo_bamai_memory_vmstat_container_pgscan_kswapd gauge
huatuo_bamai_memory_vmstat_container_pgscan_kswapd{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_container_pgsteal_direct cgroup memory.stat pgsteal_direct
# TYPE huatuo_bamai_memory_vmstat_container_pgsteal_direct gauge
huatuo_bamai_memory_vmstat_container_pgsteal_direct{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_container_pgsteal_kswapd cgroup memory.stat pgsteal_kswapd
# TYPE huatuo_bamai_memory_vmstat_container_pgsteal_kswapd gauge
huatuo_bamai_memory_vmstat_container_pgsteal_kswapd{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_container_shmem cgroup memory.stat shmem
# TYPE huatuo_bamai_memory_vmstat_container_shmem gauge
huatuo_bamai_memory_vmstat_container_shmem{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_container_shmem_thp cgroup memory.stat shmem_thp
# TYPE huatuo_bamai_memory_vmstat_container_shmem_thp gauge
huatuo_bamai_memory_vmstat_container_shmem_thp{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_container_unevictable cgroup memory.stat unevictable
# TYPE huatuo_bamai_memory_vmstat_container_unevictable gauge
huatuo_bamai_memory_vmstat_container_unevictable{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
| Metric | Description | Unit | Target | Labels |
|---|---|---|---|---|
| memory_vmstat_container_active_file | Active file-backed memory | Bytes | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| memory_vmstat_container_active_anon | Active anonymous memory | Bytes | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| memory_vmstat_container_inactive_file | Inactive file-backed memory | Bytes | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| memory_vmstat_container_inactive_anon | Inactive anonymous memory | Bytes | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| memory_vmstat_container_file_dirty | Dirty file pages not yet written back | Bytes | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| memory_vmstat_container_file_writeback | File pages currently being written back | Bytes | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| memory_vmstat_container_unevictable | Unevictable pages (mlocked, hugetlbfs, etc.) | Bytes | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| … (pgscan_direct, pgsteal_kswapd, etc.) | Standard vmstat reclaim / scanning counters | Bytes | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
Host memory state.
# HELP huatuo_bamai_memory_vmstat_allocstall_device /proc/vmstat allocstall_device
# TYPE huatuo_bamai_memory_vmstat_allocstall_device gauge
huatuo_bamai_memory_vmstat_allocstall_device{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_allocstall_dma /proc/vmstat allocstall_dma
# TYPE huatuo_bamai_memory_vmstat_allocstall_dma gauge
huatuo_bamai_memory_vmstat_allocstall_dma{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_allocstall_dma32 /proc/vmstat allocstall_dma32
# TYPE huatuo_bamai_memory_vmstat_allocstall_dma32 gauge
huatuo_bamai_memory_vmstat_allocstall_dma32{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_allocstall_movable /proc/vmstat allocstall_movable
# TYPE huatuo_bamai_memory_vmstat_allocstall_movable gauge
huatuo_bamai_memory_vmstat_allocstall_movable{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_allocstall_normal /proc/vmstat allocstall_normal
# TYPE huatuo_bamai_memory_vmstat_allocstall_normal gauge
huatuo_bamai_memory_vmstat_allocstall_normal{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_nr_active_anon /proc/vmstat nr_active_anon
# TYPE huatuo_bamai_memory_vmstat_nr_active_anon gauge
huatuo_bamai_memory_vmstat_nr_active_anon{host="hostname",region="dev"} 155449
# HELP huatuo_bamai_memory_vmstat_nr_active_file /proc/vmstat nr_active_file
# TYPE huatuo_bamai_memory_vmstat_nr_active_file gauge
huatuo_bamai_memory_vmstat_nr_active_file{host="hostname",region="dev"} 212425
# HELP huatuo_bamai_memory_vmstat_nr_dirty /proc/vmstat nr_dirty
# TYPE huatuo_bamai_memory_vmstat_nr_dirty gauge
huatuo_bamai_memory_vmstat_nr_dirty{host="hostname",region="dev"} 19047
# HELP huatuo_bamai_memory_vmstat_nr_dirty_background_threshold /proc/vmstat nr_dirty_background_threshold
# TYPE huatuo_bamai_memory_vmstat_nr_dirty_background_threshold gauge
huatuo_bamai_memory_vmstat_nr_dirty_background_threshold{host="hostname",region="dev"} 379858
# HELP huatuo_bamai_memory_vmstat_nr_dirty_threshold /proc/vmstat nr_dirty_threshold
# TYPE huatuo_bamai_memory_vmstat_nr_dirty_threshold gauge
huatuo_bamai_memory_vmstat_nr_dirty_threshold{host="hostname",region="dev"} 760646
# HELP huatuo_bamai_memory_vmstat_nr_free_pages /proc/vmstat nr_free_pages
# TYPE huatuo_bamai_memory_vmstat_nr_free_pages gauge
huatuo_bamai_memory_vmstat_nr_free_pages{host="hostname",region="dev"} 3.20535e+06
# HELP huatuo_bamai_memory_vmstat_nr_inactive_anon /proc/vmstat nr_inactive_anon
# TYPE huatuo_bamai_memory_vmstat_nr_inactive_anon gauge
huatuo_bamai_memory_vmstat_nr_inactive_anon{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_nr_inactive_file /proc/vmstat nr_inactive_file
# TYPE huatuo_bamai_memory_vmstat_nr_inactive_file gauge
huatuo_bamai_memory_vmstat_nr_inactive_file{host="hostname",region="dev"} 428518
# HELP huatuo_bamai_memory_vmstat_nr_mlock /proc/vmstat nr_mlock
# TYPE huatuo_bamai_memory_vmstat_nr_mlock gauge
huatuo_bamai_memory_vmstat_nr_mlock{host="hostname",region="dev"} 6821
# HELP huatuo_bamai_memory_vmstat_nr_shmem /proc/vmstat nr_shmem
# TYPE huatuo_bamai_memory_vmstat_nr_shmem gauge
huatuo_bamai_memory_vmstat_nr_shmem{host="hostname",region="dev"} 541
# HELP huatuo_bamai_memory_vmstat_nr_shmem_hugepages /proc/vmstat nr_shmem_hugepages
# TYPE huatuo_bamai_memory_vmstat_nr_shmem_hugepages gauge
huatuo_bamai_memory_vmstat_nr_shmem_hugepages{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_nr_shmem_pmdmapped /proc/vmstat nr_shmem_pmdmapped
# TYPE huatuo_bamai_memory_vmstat_nr_shmem_pmdmapped gauge
huatuo_bamai_memory_vmstat_nr_shmem_pmdmapped{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_nr_slab_reclaimable /proc/vmstat nr_slab_reclaimable
# TYPE huatuo_bamai_memory_vmstat_nr_slab_reclaimable gauge
huatuo_bamai_memory_vmstat_nr_slab_reclaimable{host="hostname",region="dev"} 22322
# HELP huatuo_bamai_memory_vmstat_nr_slab_unreclaimable /proc/vmstat nr_slab_unreclaimable
# TYPE huatuo_bamai_memory_vmstat_nr_slab_unreclaimable gauge
huatuo_bamai_memory_vmstat_nr_slab_unreclaimable{host="hostname",region="dev"} 24168
# HELP huatuo_bamai_memory_vmstat_nr_unevictable /proc/vmstat nr_unevictable
# TYPE huatuo_bamai_memory_vmstat_nr_unevictable gauge
huatuo_bamai_memory_vmstat_nr_unevictable{host="hostname",region="dev"} 6839
# HELP huatuo_bamai_memory_vmstat_nr_writeback /proc/vmstat nr_writeback
# TYPE huatuo_bamai_memory_vmstat_nr_writeback gauge
huatuo_bamai_memory_vmstat_nr_writeback{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_nr_writeback_temp /proc/vmstat nr_writeback_temp
# TYPE huatuo_bamai_memory_vmstat_nr_writeback_temp gauge
huatuo_bamai_memory_vmstat_nr_writeback_temp{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_numa_pages_migrated /proc/vmstat numa_pages_migrated
# TYPE huatuo_bamai_memory_vmstat_numa_pages_migrated gauge
huatuo_bamai_memory_vmstat_numa_pages_migrated{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_pgdeactivate /proc/vmstat pgdeactivate
# TYPE huatuo_bamai_memory_vmstat_pgdeactivate gauge
huatuo_bamai_memory_vmstat_pgdeactivate{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_pgrefill /proc/vmstat pgrefill
# TYPE huatuo_bamai_memory_vmstat_pgrefill gauge
huatuo_bamai_memory_vmstat_pgrefill{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_pgscan_direct /proc/vmstat pgscan_direct
# TYPE huatuo_bamai_memory_vmstat_pgscan_direct gauge
huatuo_bamai_memory_vmstat_pgscan_direct{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_pgscan_direct_throttle /proc/vmstat pgscan_direct_throttle
# TYPE huatuo_bamai_memory_vmstat_pgscan_direct_throttle gauge
huatuo_bamai_memory_vmstat_pgscan_direct_throttle{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_pgscan_kswapd /proc/vmstat pgscan_kswapd
# TYPE huatuo_bamai_memory_vmstat_pgscan_kswapd gauge
huatuo_bamai_memory_vmstat_pgscan_kswapd{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_pgsteal_direct /proc/vmstat pgsteal_direct
# TYPE huatuo_bamai_memory_vmstat_pgsteal_direct gauge
huatuo_bamai_memory_vmstat_pgsteal_direct{host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_vmstat_pgsteal_kswapd /proc/vmstat pgsteal_kswapd
# TYPE huatuo_bamai_memory_vmstat_pgsteal_kswapd gauge
huatuo_bamai_memory_vmstat_pgsteal_kswapd{host="hostname",region="dev"} 0
Standard kernel vmstat counters (see kernel documentation for full details):
- nr_free_pages: total free pages in buddy allocator
- nr_active_anon / nr_inactive_anon: active / inactive anonymous pages
- nr_active_file / nr_inactive_file: active / inactive file pages
- nr_dirty / nr_writeback: dirty / under writeback pages
- nr_dirty_threshold / nr_dirty_background_threshold: dirty page writeback thresholds
- pgscan_kswapd / pgsteal_kswapd / … : reclaim & scanning statistics
- allocstall_*: stalls due to allocation failure in different zones
- numa_hit / numa_miss / numa_foreign / numa_local / numa_other: NUMA allocation statistics
Ref:
- https://docs.kernel.org/admin-guide/cgroup-v2.html
- https://docs.kernel.org/admin-guide/cgroup-v1/memory.html
- https://docs.kernel.org/admin-guide/mm/transhuge.html
Events
From memory.events:
# HELP huatuo_bamai_memory_events_container_high memory events high
# TYPE huatuo_bamai_memory_events_container_high gauge
huatuo_bamai_memory_events_container_high{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_events_container_low memory events low
# TYPE huatuo_bamai_memory_events_container_low gauge
huatuo_bamai_memory_events_container_low{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_events_container_max memory events max
# TYPE huatuo_bamai_memory_events_container_max gauge
huatuo_bamai_memory_events_container_max{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_events_container_oom memory events oom
# TYPE huatuo_bamai_memory_events_container_oom gauge
huatuo_bamai_memory_events_container_oom{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_events_container_oom_group_kill memory events oom_group_kill
# TYPE huatuo_bamai_memory_events_container_oom_group_kill gauge
huatuo_bamai_memory_events_container_oom_group_kill{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_memory_events_container_oom_kill memory events oom_kill
# TYPE huatuo_bamai_memory_events_container_oom_kill gauge
huatuo_bamai_memory_events_container_oom_kill{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
| Metric | Description | Unit | Target | Labels |
|---|---|---|---|---|
| memory_events_container_low | Pages reclaimed below memory.low due to system pressure | count | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| memory_events_container_high | Times usage exceeded memory.high (throttling / direct reclaim triggered) | count | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| memory_events_container_max | Times approaching or hitting memory.max | count | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| memory_events_container_oom | Times OOM path entered due to memory.max | count | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| memory_events_container_oom_kill | Number of processes killed by OOM killer in cgroup | count | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| memory_events_container_oom_group_kill | Number of times entire cgroup killed by OOM | count | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
Buddyinfo
Free page block distribution per node/zone/order (from /proc/buddyinfo):
# HELP huatuo_bamai_memory_buddyinfo_blocks buddy info
# TYPE huatuo_bamai_memory_buddyinfo_blocks gauge
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="0",region="dev",zone="DMA"} 0
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="0",region="dev",zone="DMA32"} 3
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="0",region="dev",zone="Normal"} 7
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="1",region="dev",zone="DMA"} 0
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="1",region="dev",zone="DMA32"} 1
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="1",region="dev",zone="Normal"} 36
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="10",region="dev",zone="DMA"} 2
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="10",region="dev",zone="DMA32"} 743
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="10",region="dev",zone="Normal"} 2265
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="2",region="dev",zone="DMA"} 0
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="2",region="dev",zone="DMA32"} 3
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="2",region="dev",zone="Normal"} 10
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="3",region="dev",zone="DMA"} 0
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="3",region="dev",zone="DMA32"} 2
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="3",region="dev",zone="Normal"} 224
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="4",region="dev",zone="DMA"} 0
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="4",region="dev",zone="DMA32"} 1
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="4",region="dev",zone="Normal"} 376
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="5",region="dev",zone="DMA"} 0
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="5",region="dev",zone="DMA32"} 1
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="5",region="dev",zone="Normal"} 165
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="6",region="dev",zone="DMA"} 0
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="6",region="dev",zone="DMA32"} 3
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="6",region="dev",zone="Normal"} 118
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="7",region="dev",zone="DMA"} 0
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="7",region="dev",zone="DMA32"} 4
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="7",region="dev",zone="Normal"} 172
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="8",region="dev",zone="DMA"} 1
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="8",region="dev",zone="DMA32"} 4
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="8",region="dev",zone="Normal"} 35
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="9",region="dev",zone="DMA"} 2
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="9",region="dev",zone="DMA32"} 4
huatuo_bamai_memory_buddyinfo_blocks{host="hostname",node="0",order="9",region="dev",zone="Normal"} 25
| Metric | Description | Unit | Target | Labels |
|---|---|---|---|---|
| memory_buddyinfo_blocks | Shows number of free blocks of each order (2^order pages) in each zone. | count | Host | procfs |
Network
ARP
# HELP huatuo_bamai_arp_container_entries arp entries in container netns
# TYPE huatuo_bamai_arp_container_entries gauge
huatuo_bamai_arp_container_entries{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 1
# HELP huatuo_bamai_arp_entries host init namespace
# TYPE huatuo_bamai_arp_entries gauge
huatuo_bamai_arp_entries{host="hostname",region="dev"} 5
# HELP huatuo_bamai_arp_total all entries in arp_cache for containers and host netns
# TYPE huatuo_bamai_arp_total gauge
huatuo_bamai_arp_total{host="hostname",region="dev"} 12
| Metric | Description | Unit | Scope | Labels |
|---|---|---|---|---|
| arp_entries | Number of ARP entries in the host’s network namespace | count | Host namespace | host, region |
| arp_total | Total number of ARP entries across all network namespaces on the host | count | Host | host, region |
| arp_container_entries | Number of ARP entries in the container’s network namespace | count | Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
Qdisc
Qdisc (Queueing Discipline) is a key module in the Linux kernel networking subsystem. Monitoring this module provides clear visibility into network packet processing and latency behavior.
# HELP huatuo_bamai_netdev_qdisc_backlog Number of bytes currently in queue to be sent.
# TYPE huatuo_bamai_netdev_qdisc_backlog gauge
huatuo_bamai_netdev_qdisc_backlog{device="ens2",host="hostname",kind="fq_codel",region="dev"} 0
# HELP huatuo_bamai_netdev_qdisc_bytes_total Number of bytes sent.
# TYPE huatuo_bamai_netdev_qdisc_bytes_total counter
huatuo_bamai_netdev_qdisc_bytes_total{device="ens2",host="hostname",kind="fq_codel",region="dev"} 2.578235443e+09
# HELP huatuo_bamai_netdev_qdisc_current_queue_length Number of packets currently in queue to be sent.
# TYPE huatuo_bamai_netdev_qdisc_current_queue_length gauge
huatuo_bamai_netdev_qdisc_current_queue_length{device="ens2",host="hostname",kind="fq_codel",region="dev"} 0
# HELP huatuo_bamai_netdev_qdisc_drops_total Number of packet drops.
# TYPE huatuo_bamai_netdev_qdisc_drops_total counter
huatuo_bamai_netdev_qdisc_drops_total{device="ens2",host="hostname",kind="fq_codel",region="dev"} 0
# HELP huatuo_bamai_netdev_qdisc_overlimits_total Number of packet overlimits.
# TYPE huatuo_bamai_netdev_qdisc_overlimits_total counter
huatuo_bamai_netdev_qdisc_overlimits_total{device="ens2",host="hostname",kind="fq_codel",region="dev"} 0
# HELP huatuo_bamai_netdev_qdisc_packets_total Number of packets sent.
# TYPE huatuo_bamai_netdev_qdisc_packets_total counter
huatuo_bamai_netdev_qdisc_packets_total{device="ens2",host="hostname",kind="fq_codel",region="dev"} 6.867714e+06
# HELP huatuo_bamai_netdev_qdisc_requeues_total Number of packets dequeued, not transmitted, and requeued.
# TYPE huatuo_bamai_netdev_qdisc_requeues_total counter
huatuo_bamai_netdev_qdisc_requeues_total{device="ens2",host="hostname",kind="fq_codel",region="dev"} 0
| Metric | Description | Unit | Scope | Labels |
|---|---|---|---|---|
| qdisc_backlog | Bytes of packets currently queued for transmission (backlog) | Bytes | Host | device, host, kind, region |
| qdisc_current_queue_length | Number of packets currently queued | count | Host | device, host, kind, region |
| qdisc_overlimits_total | Total number of times the queue limit was exceeded | count | Host | device, host, kind, region |
| qdisc_requeues_total | Number of times packets were requeued due to temporary inability of the NIC/driver to transmit | count | Host | device, host, kind, region |
| qdisc_drops_total | Total number of packets actively dropped | count | Host | device, host, kind, region |
| qdisc_bytes_total | Total bytes transmitted | Bytes | Host | device, host, kind, region |
| qdisc_packets_total | Total number of packets transmitted | count | Host | device, host, kind, region |
Hardware
This metric tracks packets dropped by the network interface card (NIC) hardware in the receive (RX) path, typically due to buffer overflow, CRC errors, or other hardware-level issues.
# HELP huatuo_bamai_netdev_hw_rx_dropped count of packets dropped at hardware level
# TYPE huatuo_bamai_netdev_hw_rx_dropped gauge
huatuo_bamai_netdev_hw_rx_dropped{device="eth0",driver="mlx5_core",host="hostname",region="dev"} 0
| Metric | Description | Unit | Scope | Labels |
|---|---|---|---|---|
| netdev_hw_rx_dropped | Number of packets dropped by NIC hardware in the receive direction | count | Host | eBPF |
Netdev
# HELP huatuo_bamai_netdev_container_receive_bytes_total Network device statistic receive_bytes.
# TYPE huatuo_bamai_netdev_container_receive_bytes_total counter
huatuo_bamai_netdev_container_receive_bytes_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 6.4400018e+07
# HELP huatuo_bamai_netdev_container_receive_compressed_total Network device statistic receive_compressed.
# TYPE huatuo_bamai_netdev_container_receive_compressed_total counter
huatuo_bamai_netdev_container_receive_compressed_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_receive_dropped_total Network device statistic receive_dropped.
# TYPE huatuo_bamai_netdev_container_receive_dropped_total counter
huatuo_bamai_netdev_container_receive_dropped_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_receive_errors_total Network device statistic receive_errors.
# TYPE huatuo_bamai_netdev_container_receive_errors_total counter
huatuo_bamai_netdev_container_receive_errors_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_receive_fifo_total Network device statistic receive_fifo.
# TYPE huatuo_bamai_netdev_container_receive_fifo_total counter
huatuo_bamai_netdev_container_receive_fifo_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_receive_frame_total Network device statistic receive_frame.
# TYPE huatuo_bamai_netdev_container_receive_frame_total counter
huatuo_bamai_netdev_container_receive_frame_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_receive_multicast_total Network device statistic receive_multicast.
# TYPE huatuo_bamai_netdev_container_receive_multicast_total counter
huatuo_bamai_netdev_container_receive_multicast_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_receive_packets_total Network device statistic receive_packets.
# TYPE huatuo_bamai_netdev_container_receive_packets_total counter
huatuo_bamai_netdev_container_receive_packets_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 693155
# HELP huatuo_bamai_netdev_container_transmit_bytes_total Network device statistic transmit_bytes.
# TYPE huatuo_bamai_netdev_container_transmit_bytes_total counter
huatuo_bamai_netdev_container_transmit_bytes_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 6.2347911e+07
# HELP huatuo_bamai_netdev_container_transmit_carrier_total Network device statistic transmit_carrier.
# TYPE huatuo_bamai_netdev_container_transmit_carrier_total counter
huatuo_bamai_netdev_container_transmit_carrier_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_transmit_colls_total Network device statistic transmit_colls.
# TYPE huatuo_bamai_netdev_container_transmit_colls_total counter
huatuo_bamai_netdev_container_transmit_colls_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_transmit_compressed_total Network device statistic transmit_compressed.
# TYPE huatuo_bamai_netdev_container_transmit_compressed_total counter
huatuo_bamai_netdev_container_transmit_compressed_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_transmit_dropped_total Network device statistic transmit_dropped.
# TYPE huatuo_bamai_netdev_container_transmit_dropped_total counter
huatuo_bamai_netdev_container_transmit_dropped_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_transmit_errors_total Network device statistic transmit_errors.
# TYPE huatuo_bamai_netdev_container_transmit_errors_total counter
huatuo_bamai_netdev_container_transmit_errors_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_transmit_fifo_total Network device statistic transmit_fifo.
# TYPE huatuo_bamai_netdev_container_transmit_fifo_total counter
huatuo_bamai_netdev_container_transmit_fifo_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netdev_container_transmit_packets_total Network device statistic transmit_packets.
# TYPE huatuo_bamai_netdev_container_transmit_packets_total counter
huatuo_bamai_netdev_container_transmit_packets_total{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",device="eth0",host="hostname",region="dev"} 660218
| Metric | Description | Unit | Scope | Labels |
|---|---|---|---|---|
| netdev_receive_bytes_total | Total number of bytes successfully received | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_receive_packets_total | Total number of packets successfully received | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_receive_compressed_total | Number of compressed packets received | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_receive_frame_total | Number of frame alignment errors on receive | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_receive_errors_total | Total number of receive errors | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_receive_dropped_total | Number of received packets dropped by kernel or driver (various reasons) | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_receive_fifo_total | Number of receive FIFO/ring buffer overflow errors | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_transmit_bytes_total | Total number of bytes successfully transmitted | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_transmit_packets_total | Total number of packets successfully transmitted | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_transmit_errors_total | Total number of transmit errors | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_transmit_dropped_total | Number of packets dropped during transmission (queue full, policy, etc.) | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_transmit_fifo_total | Number of transmit FIFO/ring buffer errors | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_transmit_carrier_total | Number of carrier errors (link down or cable issues during transmission) | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
| netdev_transmit_compressed_total | Number of compressed packets transmitted | count | Host, Container | container_host, container_hostnamespace, container_level, container_name, container_type, host, region |
Tcp Memory
From /proc/net/netstat
# HELP huatuo_bamai_tcp_memory_limit_pages tcp memory pages limit
# TYPE huatuo_bamai_tcp_memory_limit_pages gauge
huatuo_bamai_tcp_memory_limit_pages{host="hostname",region="dev"} 380526
# HELP huatuo_bamai_tcp_memory_usage_bytes tcp memory bytes usage
# TYPE huatuo_bamai_tcp_memory_usage_bytes gauge
huatuo_bamai_tcp_memory_usage_bytes{host="hostname",region="dev"} 0
# HELP huatuo_bamai_tcp_memory_usage_pages tcp memory pages usage
# TYPE huatuo_bamai_tcp_memory_usage_pages gauge
huatuo_bamai_tcp_memory_usage_pages{host="hostname",region="dev"} 0
# HELP huatuo_bamai_tcp_memory_usage_percent tcp memory usage percent
# TYPE huatuo_bamai_tcp_memory_usage_percent gauge
huatuo_bamai_tcp_memory_usage_percent{host="hostname",region="dev"} 0
TcpExt
Linux-specific TCP extended statistics (see kernel Documentation/networking/snmp_counter.rst):
- TcpExtListenDrops / ListenOverflows: drops due to full listen queue
- TcpExtSyncookiesSent / Recv / Failed: SYN cookies handling
- TcpExtTCPRcvCoalesce: packets coalesced in receive path
- TcpExtTCPAutoCorking: packets corked automatically
- TcpExtTCPOrigDataSent: original data bytes sent (excluding retransmits)
- TcpExtTCPLossProbes / TCPLossProbeRecovery: tail loss probe statistics
- TcpExtTCPAbortOn*: various abort reasons
- … (many more – refer to kernel snmp_counter documentation for complete list)
# HELP huatuo_bamai_netstat_container_TcpExt_ArpFilter statistic TcpExtArpFilter.
# TYPE huatuo_bamai_netstat_container_TcpExt_ArpFilter gauge
huatuo_bamai_netstat_container_TcpExt_ArpFilter{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_BusyPollRxPackets statistic TcpExtBusyPollRxPackets.
# TYPE huatuo_bamai_netstat_container_TcpExt_BusyPollRxPackets gauge
huatuo_bamai_netstat_container_TcpExt_BusyPollRxPackets{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_DelayedACKLocked statistic TcpExtDelayedACKLocked.
# TYPE huatuo_bamai_netstat_container_TcpExt_DelayedACKLocked gauge
huatuo_bamai_netstat_container_TcpExt_DelayedACKLocked{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_DelayedACKLost statistic TcpExtDelayedACKLost.
# TYPE huatuo_bamai_netstat_container_TcpExt_DelayedACKLost gauge
huatuo_bamai_netstat_container_TcpExt_DelayedACKLost{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_DelayedACKs statistic TcpExtDelayedACKs.
# TYPE huatuo_bamai_netstat_container_TcpExt_DelayedACKs gauge
huatuo_bamai_netstat_container_TcpExt_DelayedACKs{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 4650
# HELP huatuo_bamai_netstat_container_TcpExt_EmbryonicRsts statistic TcpExtEmbryonicRsts.
# TYPE huatuo_bamai_netstat_container_TcpExt_EmbryonicRsts gauge
huatuo_bamai_netstat_container_TcpExt_EmbryonicRsts{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_IPReversePathFilter statistic TcpExtIPReversePathFilter.
# TYPE huatuo_bamai_netstat_container_TcpExt_IPReversePathFilter gauge
huatuo_bamai_netstat_container_TcpExt_IPReversePathFilter{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_ListenDrops statistic TcpExtListenDrops.
# TYPE huatuo_bamai_netstat_container_TcpExt_ListenDrops gauge
huatuo_bamai_netstat_container_TcpExt_ListenDrops{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_ListenOverflows statistic TcpExtListenOverflows.
# TYPE huatuo_bamai_netstat_container_TcpExt_ListenOverflows gauge
huatuo_bamai_netstat_container_TcpExt_ListenOverflows{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_LockDroppedIcmps statistic TcpExtLockDroppedIcmps.
# TYPE huatuo_bamai_netstat_container_TcpExt_LockDroppedIcmps gauge
huatuo_bamai_netstat_container_TcpExt_LockDroppedIcmps{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_OfoPruned statistic TcpExtOfoPruned.
# TYPE huatuo_bamai_netstat_container_TcpExt_OfoPruned gauge
huatuo_bamai_netstat_container_TcpExt_OfoPruned{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_OutOfWindowIcmps statistic TcpExtOutOfWindowIcmps.
# TYPE huatuo_bamai_netstat_container_TcpExt_OutOfWindowIcmps gauge
huatuo_bamai_netstat_container_TcpExt_OutOfWindowIcmps{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_PAWSActive statistic TcpExtPAWSActive.
# TYPE huatuo_bamai_netstat_container_TcpExt_PAWSActive gauge
huatuo_bamai_netstat_container_TcpExt_PAWSActive{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_PAWSEstab statistic TcpExtPAWSEstab.
# TYPE huatuo_bamai_netstat_container_TcpExt_PAWSEstab gauge
huatuo_bamai_netstat_container_TcpExt_PAWSEstab{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_PFMemallocDrop statistic TcpExtPFMemallocDrop.
# TYPE huatuo_bamai_netstat_container_TcpExt_PFMemallocDrop gauge
huatuo_bamai_netstat_container_TcpExt_PFMemallocDrop{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_PruneCalled statistic TcpExtPruneCalled.
# TYPE huatuo_bamai_netstat_container_TcpExt_PruneCalled gauge
huatuo_bamai_netstat_container_TcpExt_PruneCalled{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_RcvPruned statistic TcpExtRcvPruned.
# TYPE huatuo_bamai_netstat_container_TcpExt_RcvPruned gauge
huatuo_bamai_netstat_container_TcpExt_RcvPruned{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_SyncookiesFailed statistic TcpExtSyncookiesFailed.
# TYPE huatuo_bamai_netstat_container_TcpExt_SyncookiesFailed gauge
huatuo_bamai_netstat_container_TcpExt_SyncookiesFailed{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_SyncookiesRecv statistic TcpExtSyncookiesRecv.
# TYPE huatuo_bamai_netstat_container_TcpExt_SyncookiesRecv gauge
huatuo_bamai_netstat_container_TcpExt_SyncookiesRecv{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_SyncookiesSent statistic TcpExtSyncookiesSent.
# TYPE huatuo_bamai_netstat_container_TcpExt_SyncookiesSent gauge
huatuo_bamai_netstat_container_TcpExt_SyncookiesSent{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedChallenge statistic TcpExtTCPACKSkippedChallenge.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedChallenge gauge
huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedChallenge{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedFinWait2 statistic TcpExtTCPACKSkippedFinWait2.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedFinWait2 gauge
huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedFinWait2{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedPAWS statistic TcpExtTCPACKSkippedPAWS.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedPAWS gauge
huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedPAWS{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedSeq statistic TcpExtTCPACKSkippedSeq.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedSeq gauge
huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedSeq{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedSynRecv statistic TcpExtTCPACKSkippedSynRecv.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedSynRecv gauge
huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedSynRecv{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedTimeWait statistic TcpExtTCPACKSkippedTimeWait.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedTimeWait gauge
huatuo_bamai_netstat_container_TcpExt_TCPACKSkippedTimeWait{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAOBad statistic TcpExtTCPAOBad.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAOBad gauge
huatuo_bamai_netstat_container_TcpExt_TCPAOBad{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAODroppedIcmps statistic TcpExtTCPAODroppedIcmps.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAODroppedIcmps gauge
huatuo_bamai_netstat_container_TcpExt_TCPAODroppedIcmps{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAOGood statistic TcpExtTCPAOGood.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAOGood gauge
huatuo_bamai_netstat_container_TcpExt_TCPAOGood{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAOKeyNotFound statistic TcpExtTCPAOKeyNotFound.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAOKeyNotFound gauge
huatuo_bamai_netstat_container_TcpExt_TCPAOKeyNotFound{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAORequired statistic TcpExtTCPAORequired.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAORequired gauge
huatuo_bamai_netstat_container_TcpExt_TCPAORequired{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAbortFailed statistic TcpExtTCPAbortFailed.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAbortFailed gauge
huatuo_bamai_netstat_container_TcpExt_TCPAbortFailed{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAbortOnClose statistic TcpExtTCPAbortOnClose.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAbortOnClose gauge
huatuo_bamai_netstat_container_TcpExt_TCPAbortOnClose{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 1
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAbortOnData statistic TcpExtTCPAbortOnData.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAbortOnData gauge
huatuo_bamai_netstat_container_TcpExt_TCPAbortOnData{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAbortOnLinger statistic TcpExtTCPAbortOnLinger.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAbortOnLinger gauge
huatuo_bamai_netstat_container_TcpExt_TCPAbortOnLinger{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAbortOnMemory statistic TcpExtTCPAbortOnMemory.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAbortOnMemory gauge
huatuo_bamai_netstat_container_TcpExt_TCPAbortOnMemory{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAbortOnTimeout statistic TcpExtTCPAbortOnTimeout.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAbortOnTimeout gauge
huatuo_bamai_netstat_container_TcpExt_TCPAbortOnTimeout{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAckCompressed statistic TcpExtTCPAckCompressed.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAckCompressed gauge
huatuo_bamai_netstat_container_TcpExt_TCPAckCompressed{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPAutoCorking statistic TcpExtTCPAutoCorking.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPAutoCorking gauge
huatuo_bamai_netstat_container_TcpExt_TCPAutoCorking{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPBacklogCoalesce statistic TcpExtTCPBacklogCoalesce.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPBacklogCoalesce gauge
huatuo_bamai_netstat_container_TcpExt_TCPBacklogCoalesce{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 3
# HELP huatuo_bamai_netstat_container_TcpExt_TCPBacklogDrop statistic TcpExtTCPBacklogDrop.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPBacklogDrop gauge
huatuo_bamai_netstat_container_TcpExt_TCPBacklogDrop{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPChallengeACK statistic TcpExtTCPChallengeACK.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPChallengeACK gauge
huatuo_bamai_netstat_container_TcpExt_TCPChallengeACK{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDSACKIgnoredDubious statistic TcpExtTCPDSACKIgnoredDubious.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDSACKIgnoredDubious gauge
huatuo_bamai_netstat_container_TcpExt_TCPDSACKIgnoredDubious{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDSACKIgnoredNoUndo statistic TcpExtTCPDSACKIgnoredNoUndo.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDSACKIgnoredNoUndo gauge
huatuo_bamai_netstat_container_TcpExt_TCPDSACKIgnoredNoUndo{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 1
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDSACKIgnoredOld statistic TcpExtTCPDSACKIgnoredOld.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDSACKIgnoredOld gauge
huatuo_bamai_netstat_container_TcpExt_TCPDSACKIgnoredOld{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDSACKOfoRecv statistic TcpExtTCPDSACKOfoRecv.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDSACKOfoRecv gauge
huatuo_bamai_netstat_container_TcpExt_TCPDSACKOfoRecv{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDSACKOfoSent statistic TcpExtTCPDSACKOfoSent.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDSACKOfoSent gauge
huatuo_bamai_netstat_container_TcpExt_TCPDSACKOfoSent{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDSACKOldSent statistic TcpExtTCPDSACKOldSent.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDSACKOldSent gauge
huatuo_bamai_netstat_container_TcpExt_TCPDSACKOldSent{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDSACKRecv statistic TcpExtTCPDSACKRecv.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDSACKRecv gauge
huatuo_bamai_netstat_container_TcpExt_TCPDSACKRecv{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 1
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDSACKRecvSegs statistic TcpExtTCPDSACKRecvSegs.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDSACKRecvSegs gauge
huatuo_bamai_netstat_container_TcpExt_TCPDSACKRecvSegs{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 1
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDSACKUndo statistic TcpExtTCPDSACKUndo.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDSACKUndo gauge
huatuo_bamai_netstat_container_TcpExt_TCPDSACKUndo{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDeferAcceptDrop statistic TcpExtTCPDeferAcceptDrop.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDeferAcceptDrop gauge
huatuo_bamai_netstat_container_TcpExt_TCPDeferAcceptDrop{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDelivered statistic TcpExtTCPDelivered.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDelivered gauge
huatuo_bamai_netstat_container_TcpExt_TCPDelivered{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 3.28098e+06
# HELP huatuo_bamai_netstat_container_TcpExt_TCPDeliveredCE statistic TcpExtTCPDeliveredCE.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPDeliveredCE gauge
huatuo_bamai_netstat_container_TcpExt_TCPDeliveredCE{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPFastOpenActive statistic TcpExtTCPFastOpenActive.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPFastOpenActive gauge
huatuo_bamai_netstat_container_TcpExt_TCPFastOpenActive{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPFastOpenActiveFail statistic TcpExtTCPFastOpenActiveFail.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPFastOpenActiveFail gauge
huatuo_bamai_netstat_container_TcpExt_TCPFastOpenActiveFail{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPFastOpenBlackhole statistic TcpExtTCPFastOpenBlackhole.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPFastOpenBlackhole gauge
huatuo_bamai_netstat_container_TcpExt_TCPFastOpenBlackhole{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPFastOpenCookieReqd statistic TcpExtTCPFastOpenCookieReqd.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPFastOpenCookieReqd gauge
huatuo_bamai_netstat_container_TcpExt_TCPFastOpenCookieReqd{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPFastOpenListenOverflow statistic TcpExtTCPFastOpenListenOverflow.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPFastOpenListenOverflow gauge
huatuo_bamai_netstat_container_TcpExt_TCPFastOpenListenOverflow{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPFastOpenPassive statistic TcpExtTCPFastOpenPassive.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPFastOpenPassive gauge
huatuo_bamai_netstat_container_TcpExt_TCPFastOpenPassive{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPFastOpenPassiveAltKey statistic TcpExtTCPFastOpenPassiveAltKey.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPFastOpenPassiveAltKey gauge
huatuo_bamai_netstat_container_TcpExt_TCPFastOpenPassiveAltKey{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPFastOpenPassiveFail statistic TcpExtTCPFastOpenPassiveFail.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPFastOpenPassiveFail gauge
huatuo_bamai_netstat_container_TcpExt_TCPFastOpenPassiveFail{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPFastRetrans statistic TcpExtTCPFastRetrans.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPFastRetrans gauge
huatuo_bamai_netstat_container_TcpExt_TCPFastRetrans{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPFromZeroWindowAdv statistic TcpExtTCPFromZeroWindowAdv.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPFromZeroWindowAdv gauge
huatuo_bamai_netstat_container_TcpExt_TCPFromZeroWindowAdv{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPFullUndo statistic TcpExtTCPFullUndo.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPFullUndo gauge
huatuo_bamai_netstat_container_TcpExt_TCPFullUndo{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPHPAcks statistic TcpExtTCPHPAcks.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPHPAcks gauge
huatuo_bamai_netstat_container_TcpExt_TCPHPAcks{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 616667
# HELP huatuo_bamai_netstat_container_TcpExt_TCPHPHits statistic TcpExtTCPHPHits.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPHPHits gauge
huatuo_bamai_netstat_container_TcpExt_TCPHPHits{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 9913
# HELP huatuo_bamai_netstat_container_TcpExt_TCPHystartDelayCwnd statistic TcpExtTCPHystartDelayCwnd.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPHystartDelayCwnd gauge
huatuo_bamai_netstat_container_TcpExt_TCPHystartDelayCwnd{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPHystartDelayDetect statistic TcpExtTCPHystartDelayDetect.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPHystartDelayDetect gauge
huatuo_bamai_netstat_container_TcpExt_TCPHystartDelayDetect{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPHystartTrainCwnd statistic TcpExtTCPHystartTrainCwnd.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPHystartTrainCwnd gauge
huatuo_bamai_netstat_container_TcpExt_TCPHystartTrainCwnd{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPHystartTrainDetect statistic TcpExtTCPHystartTrainDetect.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPHystartTrainDetect gauge
huatuo_bamai_netstat_container_TcpExt_TCPHystartTrainDetect{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPKeepAlive statistic TcpExtTCPKeepAlive.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPKeepAlive gauge
huatuo_bamai_netstat_container_TcpExt_TCPKeepAlive{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 20
# HELP huatuo_bamai_netstat_container_TcpExt_TCPLossFailures statistic TcpExtTCPLossFailures.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPLossFailures gauge
huatuo_bamai_netstat_container_TcpExt_TCPLossFailures{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPLossProbeRecovery statistic TcpExtTCPLossProbeRecovery.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPLossProbeRecovery gauge
huatuo_bamai_netstat_container_TcpExt_TCPLossProbeRecovery{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPLossProbes statistic TcpExtTCPLossProbes.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPLossProbes gauge
huatuo_bamai_netstat_container_TcpExt_TCPLossProbes{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 1
# HELP huatuo_bamai_netstat_container_TcpExt_TCPLossUndo statistic TcpExtTCPLossUndo.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPLossUndo gauge
huatuo_bamai_netstat_container_TcpExt_TCPLossUndo{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPLostRetransmit statistic TcpExtTCPLostRetransmit.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPLostRetransmit gauge
huatuo_bamai_netstat_container_TcpExt_TCPLostRetransmit{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPMD5Failure statistic TcpExtTCPMD5Failure.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPMD5Failure gauge
huatuo_bamai_netstat_container_TcpExt_TCPMD5Failure{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPMD5NotFound statistic TcpExtTCPMD5NotFound.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPMD5NotFound gauge
huatuo_bamai_netstat_container_TcpExt_TCPMD5NotFound{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPMD5Unexpected statistic TcpExtTCPMD5Unexpected.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPMD5Unexpected gauge
huatuo_bamai_netstat_container_TcpExt_TCPMD5Unexpected{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPMTUPFail statistic TcpExtTCPMTUPFail.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPMTUPFail gauge
huatuo_bamai_netstat_container_TcpExt_TCPMTUPFail{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPMTUPSuccess statistic TcpExtTCPMTUPSuccess.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPMTUPSuccess gauge
huatuo_bamai_netstat_container_TcpExt_TCPMTUPSuccess{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPMemoryPressures statistic TcpExtTCPMemoryPressures.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPMemoryPressures gauge
huatuo_bamai_netstat_container_TcpExt_TCPMemoryPressures{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPMemoryPressuresChrono statistic TcpExtTCPMemoryPressuresChrono.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPMemoryPressuresChrono gauge
huatuo_bamai_netstat_container_TcpExt_TCPMemoryPressuresChrono{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPMigrateReqFailure statistic TcpExtTCPMigrateReqFailure.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPMigrateReqFailure gauge
huatuo_bamai_netstat_container_TcpExt_TCPMigrateReqFailure{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPMigrateReqSuccess statistic TcpExtTCPMigrateReqSuccess.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPMigrateReqSuccess gauge
huatuo_bamai_netstat_container_TcpExt_TCPMigrateReqSuccess{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPMinTTLDrop statistic TcpExtTCPMinTTLDrop.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPMinTTLDrop gauge
huatuo_bamai_netstat_container_TcpExt_TCPMinTTLDrop{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPOFODrop statistic TcpExtTCPOFODrop.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPOFODrop gauge
huatuo_bamai_netstat_container_TcpExt_TCPOFODrop{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPOFOMerge statistic TcpExtTCPOFOMerge.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPOFOMerge gauge
huatuo_bamai_netstat_container_TcpExt_TCPOFOMerge{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPOFOQueue statistic TcpExtTCPOFOQueue.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPOFOQueue gauge
huatuo_bamai_netstat_container_TcpExt_TCPOFOQueue{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPOrigDataSent statistic TcpExtTCPOrigDataSent.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPOrigDataSent gauge
huatuo_bamai_netstat_container_TcpExt_TCPOrigDataSent{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 2.675557e+06
# HELP huatuo_bamai_netstat_container_TcpExt_TCPPLBRehash statistic TcpExtTCPPLBRehash.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPPLBRehash gauge
huatuo_bamai_netstat_container_TcpExt_TCPPLBRehash{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPPartialUndo statistic TcpExtTCPPartialUndo.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPPartialUndo gauge
huatuo_bamai_netstat_container_TcpExt_TCPPartialUndo{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPPureAcks statistic TcpExtTCPPureAcks.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPPureAcks gauge
huatuo_bamai_netstat_container_TcpExt_TCPPureAcks{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 2.095262e+06
# HELP huatuo_bamai_netstat_container_TcpExt_TCPRcvCoalesce statistic TcpExtTCPRcvCoalesce.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPRcvCoalesce gauge
huatuo_bamai_netstat_container_TcpExt_TCPRcvCoalesce{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 3
# HELP huatuo_bamai_netstat_container_TcpExt_TCPRcvCollapsed statistic TcpExtTCPRcvCollapsed.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPRcvCollapsed gauge
huatuo_bamai_netstat_container_TcpExt_TCPRcvCollapsed{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPRcvQDrop statistic TcpExtTCPRcvQDrop.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPRcvQDrop gauge
huatuo_bamai_netstat_container_TcpExt_TCPRcvQDrop{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPRenoFailures statistic TcpExtTCPRenoFailures.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPRenoFailures gauge
huatuo_bamai_netstat_container_TcpExt_TCPRenoFailures{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPRenoRecovery statistic TcpExtTCPRenoRecovery.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPRenoRecovery gauge
huatuo_bamai_netstat_container_TcpExt_TCPRenoRecovery{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPRenoRecoveryFail statistic TcpExtTCPRenoRecoveryFail.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPRenoRecoveryFail gauge
huatuo_bamai_netstat_container_TcpExt_TCPRenoRecoveryFail{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPRenoReorder statistic TcpExtTCPRenoReorder.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPRenoReorder gauge
huatuo_bamai_netstat_container_TcpExt_TCPRenoReorder{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPReqQFullDoCookies statistic TcpExtTCPReqQFullDoCookies.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPReqQFullDoCookies gauge
huatuo_bamai_netstat_container_TcpExt_TCPReqQFullDoCookies{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPReqQFullDrop statistic TcpExtTCPReqQFullDrop.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPReqQFullDrop gauge
huatuo_bamai_netstat_container_TcpExt_TCPReqQFullDrop{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPRetransFail statistic TcpExtTCPRetransFail.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPRetransFail gauge
huatuo_bamai_netstat_container_TcpExt_TCPRetransFail{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSACKDiscard statistic TcpExtTCPSACKDiscard.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSACKDiscard gauge
huatuo_bamai_netstat_container_TcpExt_TCPSACKDiscard{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSACKReneging statistic TcpExtTCPSACKReneging.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSACKReneging gauge
huatuo_bamai_netstat_container_TcpExt_TCPSACKReneging{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSACKReorder statistic TcpExtTCPSACKReorder.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSACKReorder gauge
huatuo_bamai_netstat_container_TcpExt_TCPSACKReorder{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSYNChallenge statistic TcpExtTCPSYNChallenge.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSYNChallenge gauge
huatuo_bamai_netstat_container_TcpExt_TCPSYNChallenge{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSackFailures statistic TcpExtTCPSackFailures.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSackFailures gauge
huatuo_bamai_netstat_container_TcpExt_TCPSackFailures{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSackMerged statistic TcpExtTCPSackMerged.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSackMerged gauge
huatuo_bamai_netstat_container_TcpExt_TCPSackMerged{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSackRecovery statistic TcpExtTCPSackRecovery.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSackRecovery gauge
huatuo_bamai_netstat_container_TcpExt_TCPSackRecovery{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSackRecoveryFail statistic TcpExtTCPSackRecoveryFail.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSackRecoveryFail gauge
huatuo_bamai_netstat_container_TcpExt_TCPSackRecoveryFail{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSackShiftFallback statistic TcpExtTCPSackShiftFallback.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSackShiftFallback gauge
huatuo_bamai_netstat_container_TcpExt_TCPSackShiftFallback{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSackShifted statistic TcpExtTCPSackShifted.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSackShifted gauge
huatuo_bamai_netstat_container_TcpExt_TCPSackShifted{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSlowStartRetrans statistic TcpExtTCPSlowStartRetrans.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSlowStartRetrans gauge
huatuo_bamai_netstat_container_TcpExt_TCPSlowStartRetrans{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSpuriousRTOs statistic TcpExtTCPSpuriousRTOs.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSpuriousRTOs gauge
huatuo_bamai_netstat_container_TcpExt_TCPSpuriousRTOs{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSpuriousRtxHostQueues statistic TcpExtTCPSpuriousRtxHostQueues.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSpuriousRtxHostQueues gauge
huatuo_bamai_netstat_container_TcpExt_TCPSpuriousRtxHostQueues{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPSynRetrans statistic TcpExtTCPSynRetrans.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPSynRetrans gauge
huatuo_bamai_netstat_container_TcpExt_TCPSynRetrans{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPTSReorder statistic TcpExtTCPTSReorder.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPTSReorder gauge
huatuo_bamai_netstat_container_TcpExt_TCPTSReorder{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPTimeWaitOverflow statistic TcpExtTCPTimeWaitOverflow.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPTimeWaitOverflow gauge
huatuo_bamai_netstat_container_TcpExt_TCPTimeWaitOverflow{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPTimeouts statistic TcpExtTCPTimeouts.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPTimeouts gauge
huatuo_bamai_netstat_container_TcpExt_TCPTimeouts{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPToZeroWindowAdv statistic TcpExtTCPToZeroWindowAdv.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPToZeroWindowAdv gauge
huatuo_bamai_netstat_container_TcpExt_TCPToZeroWindowAdv{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPWantZeroWindowAdv statistic TcpExtTCPWantZeroWindowAdv.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPWantZeroWindowAdv gauge
huatuo_bamai_netstat_container_TcpExt_TCPWantZeroWindowAdv{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPWinProbe statistic TcpExtTCPWinProbe.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPWinProbe gauge
huatuo_bamai_netstat_container_TcpExt_TCPWinProbe{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPWqueueTooBig statistic TcpExtTCPWqueueTooBig.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPWqueueTooBig gauge
huatuo_bamai_netstat_container_TcpExt_TCPWqueueTooBig{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TCPZeroWindowDrop statistic TcpExtTCPZeroWindowDrop.
# TYPE huatuo_bamai_netstat_container_TcpExt_TCPZeroWindowDrop gauge
huatuo_bamai_netstat_container_TcpExt_TCPZeroWindowDrop{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TW statistic TcpExtTW.
# TYPE huatuo_bamai_netstat_container_TcpExt_TW gauge
huatuo_bamai_netstat_container_TcpExt_TW{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 720624
# HELP huatuo_bamai_netstat_container_TcpExt_TWKilled statistic TcpExtTWKilled.
# TYPE huatuo_bamai_netstat_container_TcpExt_TWKilled gauge
huatuo_bamai_netstat_container_TcpExt_TWKilled{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TWRecycled statistic TcpExtTWRecycled.
# TYPE huatuo_bamai_netstat_container_TcpExt_TWRecycled gauge
huatuo_bamai_netstat_container_TcpExt_TWRecycled{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 2461
# HELP huatuo_bamai_netstat_container_TcpExt_TcpDuplicateDataRehash statistic TcpExtTcpDuplicateDataRehash.
# TYPE huatuo_bamai_netstat_container_TcpExt_TcpDuplicateDataRehash gauge
huatuo_bamai_netstat_container_TcpExt_TcpDuplicateDataRehash{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_netstat_container_TcpExt_TcpTimeoutRehash statistic TcpExtTcpTimeoutRehash.
# TYPE huatuo_bamai_netstat_container_TcpExt_TcpTimeoutRehash gauge
huatuo_bamai_netstat_container_TcpExt_TcpTimeoutRehash{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
Ref:
Socket
# HELP huatuo_bamai_sockstat_container_FRAG_inuse Number of FRAG sockets in state inuse.
# TYPE huatuo_bamai_sockstat_container_FRAG_inuse gauge
huatuo_bamai_sockstat_container_FRAG_inuse{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_sockstat_container_FRAG_memory Number of FRAG sockets in state memory.
# TYPE huatuo_bamai_sockstat_container_FRAG_memory gauge
huatuo_bamai_sockstat_container_FRAG_memory{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_sockstat_container_RAW_inuse Number of RAW sockets in state inuse.
# TYPE huatuo_bamai_sockstat_container_RAW_inuse gauge
huatuo_bamai_sockstat_container_RAW_inuse{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_sockstat_container_TCP_alloc Number of TCP sockets in state alloc.
# TYPE huatuo_bamai_sockstat_container_TCP_alloc gauge
huatuo_bamai_sockstat_container_TCP_alloc{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 171
# HELP huatuo_bamai_sockstat_container_TCP_inuse Number of TCP sockets in state inuse.
# TYPE huatuo_bamai_sockstat_container_TCP_inuse gauge
huatuo_bamai_sockstat_container_TCP_inuse{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 1
# HELP huatuo_bamai_sockstat_container_TCP_orphan Number of TCP sockets in state orphan.
# TYPE huatuo_bamai_sockstat_container_TCP_orphan gauge
huatuo_bamai_sockstat_container_TCP_orphan{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_sockstat_container_TCP_tw Number of TCP sockets in state tw.
# TYPE huatuo_bamai_sockstat_container_TCP_tw gauge
huatuo_bamai_sockstat_container_TCP_tw{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 75
# HELP huatuo_bamai_sockstat_container_UDPLITE_inuse Number of UDPLITE sockets in state inuse.
# TYPE huatuo_bamai_sockstat_container_UDPLITE_inuse gauge
huatuo_bamai_sockstat_container_UDPLITE_inuse{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_sockstat_container_UDP_inuse Number of UDP sockets in state inuse.
# TYPE huatuo_bamai_sockstat_container_UDP_inuse gauge
huatuo_bamai_sockstat_container_UDP_inuse{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 0
# HELP huatuo_bamai_sockstat_container_sockets_used Number of IPv4 sockets in use.
# TYPE huatuo_bamai_sockstat_container_sockets_used gauge
huatuo_bamai_sockstat_container_sockets_used{container_host="coredns-855c4dd65d-8v5kg",container_hostnamespace="kube-system",container_level="burstable",container_name="coredns",container_type="normal",host="hostname",region="dev"} 7
# HELP huatuo_bamai_sockstat_sockets_used Number of IPv4 sockets in use.
# TYPE huatuo_bamai_sockstat_sockets_used gauge
huatuo_bamai_sockstat_sockets_used{host="hostname",region="dev"} 409
| Metric | Description | Unit | Scope | Labels |
|---|---|---|---|---|
| sockstat_sockets_used | Total number of sockets currently in use on the system | count | Host | |
| sockstat_TCP_inuse | Number of TCP sockets in active connection states | count | Host, Container | |
| sockstat_TCP_orphan | Number of TCP sockets without an owning process | count | Host, Container | |
| sockstat_TCP_tw | Number of TCP sockets currently in TIME_WAIT state | count | Host, Container | |
| sockstat_TCP_alloc | Total number of allocated TCP socket objects | count | Host, Container | |
| sockstat_TCP_mem | Number of memory pages currently used by TCP sockets | count | Host |
IO
iolatency tracks disk I/O latency distribution. A simple way to read it is: break one disk request into stages, then count how many requests fall into each latency bucket.
q2c: from entering the queue to completion, covering the full I/O lifecycled2c: from driver dispatch to completion, closer to device-side latencyfreeze: number of disk freeze events
The current version exposes both host-level and container-level metrics.
Queue
These metrics always include the common labels host and region. Container
metrics also always include container_host, container_name,
container_type, container_level, and container_hostnamespace.
# HELP huatuo_bamai_iolatency_blkdisk_d2c the disk d2c latency
# TYPE huatuo_bamai_iolatency_blkdisk_d2c gauge
huatuo_bamai_iolatency_blkdisk_d2c{disk="253:1",host="hostname",region="dev",zone="0"} 3
# HELP huatuo_bamai_iolatency_blkdisk_q2c the disk q2c latency
# TYPE huatuo_bamai_iolatency_blkdisk_q2c gauge
huatuo_bamai_iolatency_blkdisk_q2c{disk="253:1",host="hostname",region="dev",zone="0"} 3
# HELP huatuo_bamai_iolatency_container_blkdisk_d2c container blkio d2c latency
# TYPE huatuo_bamai_iolatency_container_blkdisk_d2c gauge
huatuo_bamai_iolatency_container_blkdisk_d2c{container_host="etcd-hostname",container_hostnamespace="kube-system",container_level="burstable",container_name="etcd",container_type="normal",disk="253:1",host="hostname",region="dev",zone="5"} 2
# HELP huatuo_bamai_iolatency_container_blkdisk_q2c container blkio q2c latency
# TYPE huatuo_bamai_iolatency_container_blkdisk_q2c gauge
huatuo_bamai_iolatency_container_blkdisk_q2c{container_host="etcd-hostname",container_hostnamespace="kube-system",container_level="burstable",container_name="etcd",container_type="normal",disk="253:1",host="hostname",region="dev",zone="5"} 2
| Metric | Description | Unit | Scope | Labels |
|---|---|---|---|---|
| iolatency_blkdisk_q2c | Host disk latency statistics for the full I/O lifecycle, from queueing to completion. Buckets: zone0 20-30ms, zone1 30-50ms, zone2 50-100ms, zone3 100-200ms, zone4 200-400ms, zone5 400ms+ | count | Host | host, region, disk, zone |
| iolatency_blkdisk_d2c | Host disk latency statistics from driver dispatch to completion, closer to device processing time. Buckets: zone0 20-30ms, zone1 30-50ms, zone2 50-100ms, zone3 100-200ms, zone4 200-400ms, zone5 400ms+ | count | Host | host, region, disk, zone |
| iolatency_container_blkdisk_q2c | Container-caused latency statistics for the full I/O lifecycle, from queueing to completion. Buckets: zone0 20-30ms, zone1 30-50ms, zone2 50-100ms, zone3 100-200ms, zone4 200-400ms, zone5 400ms+ | count | Container | host, region, container_host, container_name, container_type, container_level, container_hostnamespace, zone |
| iolatency_container_blkdisk_d2c | Container-caused latency statistics from driver dispatch to completion. Buckets: zone0 20-30ms, zone1 30-50ms, zone2 50-100ms, zone3 100-200ms, zone4 200-400ms, zone5 400ms+ | count | Container | host, region, container_host, container_name, container_type, container_level, container_hostnamespace, zone |
Hardware
# HELP huatuo_bamai_iolatency_blkdisk_freeze the disk freeze event count
# TYPE huatuo_bamai_iolatency_blkdisk_freeze gauge
huatuo_bamai_iolatency_blkdisk_freeze{disk="253:1",host="hostname",region="dev"} 0
| Metric | Description | Unit | Scope | Labels |
|---|---|---|---|---|
| iolatency_blkdisk_freeze | Host disk freeze event count | count | Host | host, region, disk |
General System
Soft Lockup
# HELP huatuo_bamai_softlockup_total softlockup counter
# TYPE huatuo_bamai_softlockup_total counter
huatuo_bamai_softlockup_total{host="hostname",region="dev"} 0
| Metric | Description | Unit | Target | Source | Labels |
|---|---|---|---|---|---|
| softlockup_total | Count of soft lockup events | count | Host | BPF |
HungTask
# HELP huatuo_bamai_hungtask_total hungtask counter
# TYPE huatuo_bamai_hungtask_total counter
huatuo_bamai_hungtask_total{host="hostname",region="dev"} 0
| Metric | Description | Unit | Target | Source | Labels |
|---|---|---|---|---|---|
| hungtask_total | Count of hung task events | count | Host | BPF |
GPU
- MetaX
| Metric | Description | Unit | Target | Source |
|---|---|---|---|---|
| metax_gpu_sdk_info | GPU SDK info. | - | version | sml.GetSDKVersion |
| metax_gpu_driver_info | GPU driver info. | - | version | sml.GetGPUVersion with driver unit |
| metax_gpu_info | GPU info. | - | gpu, model, uuid, bios_version, bdf, mode, die_count | sml.GetGPUInfo |
| metax_gpu_board_power_watts | GPU board power. | W | gpu | sml.ListGPUBoardWayElectricInfos |
| metax_gpu_pcie_link_speed_gt_per_second | GPU PCIe current link speed. | GT/s | gpu | sml.GetGPUPcieLinkInfo |
| metax_gpu_pcie_link_width_lanes | GPU PCIe current link width. | lanes | gpu | sml.GetGPUPcieLinkInfo |
| metax_gpu_pcie_receive_bytes_per_second | GPU PCIe receive throughput. | B/s | gpu | sml.GetGPUPcieThroughputInfo |
| metax_gpu_pcie_transmit_bytes_per_second | GPU PCIe transmit throughput. | B/s | gpu | sml.GetGPUPcieThroughputInfo |
| metax_gpu_metaxlink_link_speed_gt_per_second | GPU MetaXLink current link speed. | GT/s | gpu, metaxlink | sml.ListGPUMetaXLinkLinkInfos |
| metax_gpu_metaxlink_link_width_lanes | GPU MetaXLink current link width. | lanes | gpu, metaxlink | sml.ListGPUMetaXLinkLinkInfos |
| metax_gpu_metaxlink_receive_bytes_per_second | GPU MetaXLink receive throughput. | B/s | gpu, metaxlink | sml.ListGPUMetaXLinkThroughputInfos |
| metax_gpu_metaxlink_transmit_bytes_per_second | GPU MetaXLink transmit throughput. | B/s | gpu, metaxlink | sml.ListGPUMetaXLinkThroughputInfos |
| metax_gpu_metaxlink_receive_bytes_total | GPU MetaXLink receive data size. | bytes | gpu, metaxlink | sml.ListGPUMetaXLinkTrafficStatInfos |
| metax_gpu_metaxlink_transmit_bytes_total | GPU MetaXLink transmit data size. | bytes | gpu, metaxlink | sml.ListGPUMetaXLinkTrafficStatInfos |
| metax_gpu_metaxlink_aer_errors_total | GPU MetaXLink AER errors count. | count | gpu, metaxlink, error_type | sml.ListGPUMetaXLinkAerErrorsInfos |
| metax_gpu_status | GPU status, 0 means normal, other values means abnormal. Check the documentation to see the exceptions corresponding to each value. | - | gpu, die | sml.GetDieStatus |
| metax_gpu_temperature_celsius | GPU temperature. | °C | gpu, die | sml.GetDieTemperature |
| metax_gpu_utilization_percent | GPU utilization, ranging from 0 to 100. | % | gpu, die, ip | sml.GetDieUtilization |
| metax_gpu_memory_total_bytes | Total vram. | bytes | gpu, die | sml.GetDieMemoryInfo |
| metax_gpu_memory_used_bytes | Used vram. | bytes | gpu, die | sml.GetDieMemoryInfo |
| metax_gpu_clock_mhz | GPU clock. | MHz | gpu, die, ip | sml.ListDieClocks |
| metax_gpu_clocks_throttling | Reason(s) for GPU clocks throttling. | - | gpu, die, reason | sml.GetDieClocksThrottleStatus |
| metax_gpu_dpm_performance_level | GPU DPM performance level. | - | gpu, die, ip | sml.GetDieDPMPerformanceLevel |
| metax_gpu_ecc_memory_errors_total | GPU ECC memory errors count. | count | gpu, die, memory_type, error_type | sml.GetDieECCMemoryInfo |
| metax_gpu_ecc_memory_retired_pages_total | GPU ECC memory retired pages count. | count | gpu, die | sml.GetDieECCMemoryInfo |
5.2 - Instant Observability
📖 Overview
HUATUO uses eBPF technology to observe anomalous events in real time across core Linux kernel subsystems, including CPU scheduling, memory management, the network protocol stack, and hardware error reporting. When the kernel encounters anomalies such as softlockup, OOM, or hardware MCE errors, eBPF programs hook into kernel functions (kprobes) or kernel tracepoints, capturing process information, kernel call stacks, and network context at the moment the event occurs. The data is passed to user-space handlers via the perf event ring buffer and persisted to Elasticsearch or local disk files.
Compared to traditional kernel log (dmesg/syslog) collection, eBPF-based event observation reduces the risk of data loss from log buffer overflow; it can capture transient anomalies that never appear in kernel logs (such as excessive softirq disable time); and it provides container-level event correlation for precise root-cause analysis in cloud-native environments.
Eleven event types are continuously observed, covering CPU scheduling health (softirq_tracing, softlockup, hungtask), memory pressure (oom, memory_reclaim_events), the network protocol stack (dropwatch, net_rx_latency, netdev_events, netdev_bonding_lacp, netdev_txqueue_timeout), and hardware reliability (ras).
🎯 Use Cases
Kubernetes Container Memory Fault Diagnosis: In scenarios where containers frequently restart due to OOM, the oom event records both the process killed by the OOM Killer (victim) and the process that triggered the OOM (trigger), including their memcg cgroup pointers and container IDs. Combined with time-series data, this enables fast root-cause analysis of containers involved in memory contention, reducing the time spent manually reviewing container logs.
AI Training Cluster Hardware Fault Detection: On GPU training servers, the ras event continuously collects MCE (Machine Check Exception), EDAC memory controller errors, and PCIe AER (Advanced Error Reporting) errors, classifying them by severity (Corrected / UncorrectedRecoverable / UncorrectedFatal). This enables early detection of hardware aging or single-point failures before training jobs are interrupted, reducing training task losses caused by hardware faults.
Network Performance Jitter Analysis: The dropwatch event observes TCP protocol stack packet drops (including syn_flood and listen_overflow types), while net_rx_latency detects end-to-end receive-path latency for individual packets from the network card driver to user space. Separate thresholds are configured per stage (driver to kernel: 5ms, kernel to TCP: 10ms, TCP to user space: 115ms), precisely identifying which network layer causes business timeouts.
Host Scheduling Health Observation: The softirq_tracing (softirq disable time, default threshold 10ms), softlockup (CPU unable to schedule, ~1 second), and hungtask (D-state process hang) events jointly cover anomalies along the CPU scheduling path. When system stalls or response timeouts occur, kernel call stacks and other diagnostic data are automatically preserved, supporting offline analysis after the fault clears.
🚀 Usage
Configuration
All events provide default values and are operational without any configuration. The following parameters can be tuned as needed:
| Parameter | Default | Description |
|---|---|---|
softirq.disabled_threshold |
10000000 (10ms, nanoseconds) |
Softirq disable time trigger threshold |
memory_reclaim.blocked_threshold |
900000000 (900ms, nanoseconds) |
Direct memory reclaim time trigger threshold |
net_rx_latency.driver2net_rx |
5 (ms) |
Latency threshold from NIC driver to __netif_receive_skb |
net_rx_latency.driver2tcp |
10 (ms) |
Latency threshold from NIC driver to tcp_v4_rcv |
net_rx_latency.driver2userspace |
115 (ms) |
Latency threshold from NIC driver to user-space copy (skb_copy_datagram_iovec) |
net_rx_latency.excluded_host_netnamespace |
true |
Whether to exclude the host network namespace (observe containers only by default) |
net_rx_latency.excluded_container_qos |
[] |
List of container QoS levels to exclude |
dropwatch.excluded_neigh_invalidate |
true |
Whether to filter packet drops caused by neigh_invalidate (neighbor table expiry noise) |
netdev.device_list |
[] |
List of network device names to monitor for link state changes |
ras.mce_thr_backoff |
1800 (seconds) |
MCE threshold interrupt (THR) event reporting cooldown to suppress interrupt storms |
issues_list |
[] |
Known-issue filter rules (applied to net_rx_latency) |
Supported Events
| Event Name (tracer_name) | Probe Type | Trigger Condition | Typical Scenarios |
|---|---|---|---|
softirq_tracing |
kprobe | Softirq disable time > threshold (default 10ms) | System stalls, network latency, scheduling delays |
softlockup |
kprobe | CPU unable to schedule for extended time (~1 second) | Soft lockup, response anomalies |
hungtask |
kprobe | D-state process task hang | Transient mass D-state processes, IO blocking |
oom |
kprobe | OOM Killer triggered | Container/host memory exhaustion |
memory_reclaim_events |
kprobe | Container process direct reclaim time > threshold (default 900ms) | Business stalls caused by memory pressure |
ras |
tracepoint | CPU/MEM/PCIe hardware errors | Hardware fault detection |
dropwatch |
kprobe | TCP protocol stack packet drop | Business jitter caused by protocol stack drops |
net_rx_latency |
kprobe | Protocol stack receive latency exceeds per-stage threshold | Business timeouts caused by receive latency |
netdev_events |
netlink | NIC link state change | Physical NIC link failures |
netdev_bonding_lacp |
kprobe | LACP protocol state change (IEEE 802.3ad mode only) | Fault boundary between physical machines and switches |
netdev_txqueue_timeout |
kprobe | NIC transmit queue timeout | NIC transmit queue hardware failure |
Fields
All event records include the following common fields:
- hostname: Physical machine hostname
- region: Availability zone where the physical machine is located
- uploaded_time: Data upload time
- container_id: Container ID if the event is associated with a container
- container_hostname: Container hostname if the event is associated with a container
- container_host_namespace: Kubernetes namespace of the container if the event is associated with a container
- container_type: Container type, e.g.,
normalfor regular containers,sidecarfor sidecar containers - container_qos: Container QoS level
- tracer_name: Event name (e.g.,
softirq_tracing,oom) - tracer_id: Tracing ID for this event
- tracer_time: Time when the tracing was triggered
- tracer_type: Trigger type — manual or automatic
- tracer_data: Event-specific private data (see individual event descriptions below)
1. softirq_tracing
Description Triggered when the kernel disables softirqs for longer than the configured threshold. Records the kernel call stack during the disable period and current process information to help analyze interrupt-related latency issues. The filter automatically excludes noise events from ksoftirqd and swapper processes.
Data Storage Event data is automatically stored in Elasticsearch or as files on the physical machine disk.
Sample Data
{
"uploaded_time": "2025-06-11T16:05:16.251152703+08:00",
"hostname": "***",
"tracer_data": {
"offtime": 237328905,
"threshold": 10000000,
"comm": "***-agent",
"pid": 688073,
"cpu": 1,
"now": 5532940660025295,
"stack": "scheduler_tick/..."
},
"tracer_time": "2025-06-11 16:05:16.251 +0800",
"tracer_type": "auto",
"time": "2025-06-11 16:05:16.251 +0800",
"region": "***",
"tracer_name": "softirq_tracing"
}
Fields
- comm: Name of the process that triggered the event
- stack: Kernel call stack during the softirq disable period
- now: Monotonic clock timestamp at the time of the event (nanoseconds)
- offtime: Duration that softirqs were disabled (nanoseconds)
- cpu: CPU number where the event occurred
- threshold: Trigger threshold (nanoseconds); events are recorded when this is exceeded
- pid: Process ID that triggered the event
2. dropwatch
Description Detects packet drop behavior in the kernel network protocol stack. Outputs the kernel call stack, network 5-tuple, and TCP state at the time of the drop. Supports identifying four drop types: common_drop, syn_flood, listen_overflow_handshake1 (SYN queue overflow), and listen_overflow_handshake3 (accept queue overflow). The filter excludes known noisy drops including neigh_invalidate neighbor table expiry (configurable) and bnxt driver TX-side drops.
Data Storage Automatically stored in Elasticsearch or as files on the physical machine disk.
Sample Data
{
"tracer_data": {
"type": "common_drop",
"comm": "kubelet",
"pid": 1687046,
"saddr": "10.79.68.62",
"daddr": "10.134.72.4",
"sport": 8080,
"dport": 49000,
"src_hostname": "<nil>",
"dest_hostname": "<nil>",
"max_ack_backlog": 128,
"seq": 1009085774,
"ack_seq": 689410995,
"pkt_len": 1460,
"sk_state": "ESTABLISHED",
"stack": "kfree_skb/...",
"netdev_queue_mapping": 3,
"netdev_linkstatus": ["linkStatusUp"],
"netdev_name": "eth0",
"netdev_ifindex": 2,
"net_cookie": 123456789
}
}
Fields
- type: Drop type (
common_drop/syn_flood/listen_overflow_handshake1/listen_overflow_handshake3) - comm: Name of the process that triggered the packet drop
- pid: Process ID
- saddr / daddr: Source IP / Destination IP address
- sport / dport: Source port / Destination port
- src_hostname / dest_hostname: Reverse DNS lookup result for source/destination IP
- max_ack_backlog: Maximum accept queue length of the socket
- seq / ack_seq: TCP sequence number / Acknowledgment sequence number
- pkt_len: Packet length (bytes)
- sk_state: TCP connection state at the time of the drop
- stack: Kernel call stack at the time of the drop
- netdev_queue_mapping: NIC queue index
- netdev_linkstatus: List of NIC link status flags
- netdev_name: Network device name
- netdev_ifindex: Network interface index
- net_cookie: Network namespace identifier
3. net_rx_latency
Description Detects latency events on the protocol stack receive path (NIC driver → kernel protocol stack → user-space receive). Three observation points are set along the receive path; when the latency of any stage exceeds the corresponding threshold (defaults: driver to kernel 5ms, kernel to TCP 10ms, TCP to user space 115ms), the event is recorded with the network 5-tuple, TCP sequence number, latency stage, and latency duration. All TCP states are observed, not limited to ESTABLISHED—receive latency events in SYN, FIN, TIME_WAIT, and other non-ESTABLISHED states are also captured. The host network namespace is excluded by default, observing only container network traffic.
Data Storage Automatically stored in Elasticsearch or as files on the physical machine disk.
Sample Data
{
"tracer_data": {
"comm": "nginx",
"pid": 2921092,
"lat_stage": "RX_STAGE_USERCOPY",
"lat_ms": 95973,
"tcp_state": "ESTABLISHED",
"tcp_saddr": "10.156.248.76",
"tcp_daddr": "10.134.72.4",
"tcp_sport": 9213,
"tcp_dport": 49000,
"tcp_seq": 1009085774,
"tcp_ack_seq": 689410995,
"net_namespace_cookie": 123456789,
"net_namespace_inode": 402653184,
"pkt_len": 26064
}
}
Fields
- comm: Name of the process that triggered the event
- pid: Process ID that triggered the event
- lat_stage: Stage where latency occurred (
RX_STAGE_NETIFdriver-to-kernel /RX_STAGE_TCPV4kernel-to-TCP /RX_STAGE_USERCOPYTCP-to-user-space) - lat_ms: Actual latency (milliseconds)
- tcp_state: TCP connection state (all states are supported, e.g.,
ESTABLISHED,SYN_SENT,FIN_WAIT,TIME_WAIT) - tcp_saddr / tcp_daddr: Source IP / Destination IP address
- tcp_sport / tcp_dport: Source port / Destination port
- tcp_seq / tcp_ack_seq: TCP sequence number / Acknowledgment sequence number
- net_namespace_cookie: Network namespace cookie (available on kernel ≥ 5.14, used for efficient container association)
- net_namespace_inode: Network namespace inode
- pkt_len: Packet length (bytes)
4. oom
Description Detects OOM (Out of Memory) events on the host or inside containers. Records information about the process killed by the OOM Killer (victim) and the process that triggered the OOM (trigger), along with the corresponding container and memory cgroup details, providing a complete fault snapshot. Host-level and per-container OOM count metrics are also maintained.
Data Storage Automatically stored in Elasticsearch or as files on the physical machine disk.
Sample Data
{
"tracer_data": {
"trigger_memcg_css": "0xff4b8d8be3818000",
"trigger_container_id": "***",
"trigger_container_hostname": "***.docker",
"trigger_pid": 3218804,
"trigger_process_name": "java",
"victim_memcg_css": "0xff4b8d8be3818000",
"victim_container_id": "***",
"victim_container_hostname": "***.docker",
"victim_pid": 3218745,
"victim_process_name": "java",
"cgroup_memory_limit": 2147483648,
"cgroup_memory_usage": 2143289344,
"memory_snapshot": {
"top_processes": [
{
"pid": 3218745,
"process_name": "java",
"vm_rss": 1604321280,
"rss_anon": 1509949440,
"rss_file": 83886080,
"rss_shmem": 0,
"vm_swap": 0,
"total": 1593835520
}
],
"host_meminfo": {
"MemAvailable": 3355443200,
"Cached": 1073741824,
"Slab": 268435456
},
"victim_cgroup": {
"container_id": "***",
"cgroup_path": "kubepods.slice/...",
"current": 2143289344,
"max": 2147483648,
"stat": {
"anon": 1509949440,
"file": 83886080
},
"events": {
"oom": 1,
"oom_kill": 1
}
}
}
}
}
Fields
- victim_process_name / victim_pid: Name and PID of the process killed by the OOM Killer
- victim_container_hostname / victim_container_id: Hostname and container ID where the killed process resided
- victim_memcg_css: Memory cgroup pointer (hex) of the killed process
- trigger_process_name / trigger_pid: Name and PID of the process that triggered OOM
- trigger_container_hostname / trigger_container_id: Hostname and container ID where the triggering process resided
- trigger_memcg_css: Memory cgroup pointer (hex) of the triggering process
- cgroup_memory_limit / cgroup_memory_usage: Memory limit and usage reported by the kernel event
- memory_snapshot.top_processes: Top processes by RSS/swap at the OOM moment, including
RssAnon,RssFile,RssShmem,VmRSS, andVmSwap - memory_snapshot.host_meminfo: Key host
/proc/meminfovalues, such asMemAvailable,Cached,Slab, swap, and anon/file activity - memory_snapshot.trigger_cgroup / victim_cgroup: Trigger/victim container cgroup path, current/max memory,
memory.stat, andmemory.events
5. softlockup
Description Detects softlockup events (CPU unable to be scheduled for an extended period, approximately 1 second). Provides information about the target process causing the lockup, the CPU where it occurred, and NMI backtrace information for all CPUs. A backoff strategy is applied: the reporting interval increases from 10 minutes up to a maximum of 3 hours during an event storm to prevent duplicate reports. A softlockup occurrence counter metric is also maintained.
Data Storage Automatically stored in Elasticsearch or as files on the physical machine disk.
Sample Data
{
"tracer_data": {
"cpu": 15,
"pid": 12345,
"comm": "kworker/15:0",
"cpus_stack": "2025-06-10 14:30:22 sysrq: Show backtrace of all active CPUs\nNMI backtrace for cpu 15\n..."
}
}
Fields
- cpu: CPU number where the softlockup occurred
- pid: PID of the process that triggered the softlockup
- comm: Name of the process that triggered the softlockup
- cpus_stack: NMI backtrace for all CPUs (multi-line text containing timestamps and call stacks)
6. hungtask
Description Detects hungtask events. Captures the kernel stacks of all processes in D state (uninterruptible sleep) and NMI backtrace for all CPUs to preserve the fault scene. A backoff strategy is applied: the reporting interval increases from 10 minutes up to a maximum of 3 hours during an event storm. A hungtask occurrence counter metric is also maintained. Note: some Linux distributions (e.g., Fedora 42) disable hungtask detection by default, in which case this observer will not start.
Data Storage Automatically stored in Elasticsearch or as files on the physical machine disk.
Sample Data
{
"tracer_data": {
"pid": 2567042,
"comm": "kworker/u48:2",
"cpus_stack": "2025-06-10 09:57:14 sysrq: Show backtrace of all active CPUs\nNMI backtrace for cpu 33\n...",
"blocked_processes_stack": "task:java state:D stack: 0 pid: 12345 ..."
}
}
Fields
- pid: PID of the process that triggered the hungtask detection
- comm: Name of the process that triggered the hungtask detection
- cpus_stack: NMI backtrace for all CPUs (multi-line text containing timestamps and call stacks)
- blocked_processes_stack: Kernel stack information of D-state processes
7. memory_reclaim_events
Description Detects direct memory reclaim events for container processes. Triggered when the direct reclaim time of the same process within 1 second exceeds the configured threshold (default 900ms). Records the reclaim duration, process, and container information. Note: this observer only records events for container processes; host process events are filtered out.
Data Storage Automatically stored in Elasticsearch or as files on the physical machine disk.
Sample Data
{
"tracer_data": {
"pid": 1896137,
"comm": "java",
"deltatime": 1412702917
}
}
Fields
- comm: Name of the process that triggered direct memory reclaim
- pid: PID of the triggering process
- deltatime: Direct reclaim duration (nanoseconds)
8. ras
Description Detects hardware errors from CPU, memory, and PCIe subsystems via kernel tracepoints. Supports five hardware error sources: MCE (Machine Check Exception), EDAC (memory controller), ACPI/GHES (non-standard hardware errors), PCIe AER (Advanced Error Reporting), and MCE threshold interrupts (THR). Errors are classified by severity: Corrected, UncorrectedRecoverable, UncorrectedDeferred, and UncorrectedFatal. MCE threshold interrupt events use a cooldown period (default 30 minutes) to suppress interrupt storm-driven duplicate reports.
Data Storage Automatically stored in Elasticsearch or as files on the physical machine disk.
MCE Sample Data
{
"tracer_data": {
"dev": "CPU/MEM",
"event": "MCE",
"type": "UncorrectedRecoverable",
"timestamp": 1749600000000000000,
"info": "{\"mcg_cpu_cap\":4096,\"banks_msr_status\":9295429630892703744,\"cpu\":2,\"socketid\":0,\"bank\":5}"
}
}
PCIe AER Sample Data
{
"tracer_data": {
"dev": "PCIe 0000:3b:00.0",
"event": "AER",
"type": "UncorrectedRecoverable",
"timestamp": 1749600000000000000,
"info": "{\"dev_name\":\"0000:3b:00.0\",\"err_type\":\"UncorrectedRecoverable\",\"err_reason\":\"Completion Timeout\",\"tlp_header\":\"not available\"}"
}
}
Fields
- dev: Hardware device where the error occurred (e.g.,
CPU/MEM,PCIe 0000:3b:00.0) - event: Error type (
MCE/EDAC/NON_STANDARD/AER/MCE_THRESHOLD) - type: Error severity (
Corrected/UncorrectedRecoverable/UncorrectedDeferred/UncorrectedFatal/Info) - timestamp: Timestamp when the hardware error occurred
- info: JSON-formatted detailed error information; content varies by event type
9. netdev_events
Description Detects NIC link state change events by subscribing to kernel netlink RTM_NEWLINK messages. Captures events including down/up transitions, MTU changes, AdminDown, and CarrierDown, along with interface name, link status, MAC address, and driver information. At startup, the observer scans the current state of all devices in device_list as a baseline; only state changes are reported thereafter.
Data Storage Automatically stored in Elasticsearch or as files on the physical machine disk.
Sample Data
{
"tracer_data": {
"ifname": "eth1",
"index": 3,
"linkstatus": "linkStatusAdminDown, linkStatusCarrierDown",
"mac": "5c:6f:69:34:dc:72",
"start": false,
"driver": "ixgbe",
"driver_version": "5.1.0-k",
"firmware_version": "3.25 0x80000421 1.2163.0"
}
}
Fields
- ifname: Network interface name (e.g.,
eth1) - index: Interface index number
- linkstatus: Link state change description (may contain multiple states)
- mac: NIC MAC address
- start: Whether this is a baseline event scanned at startup (
true: startup scan,false: real-time change event) - driver: NIC driver name
- driver_version: NIC driver version
- firmware_version: NIC firmware version
10. netdev_bonding_lacp
Description Detects LACP (Link Aggregation Control Protocol, IEEE 802.3ad) protocol state changes in bonding mode. Reads and records the complete status of all bonding interfaces under /proc/net/bonding/, including mode, MII status, Actor/Partner negotiation parameters, and slave link states. This observer is only activated automatically when an IEEE 802.3ad bonding interface is present on the system.
Data Storage Automatically stored in Elasticsearch or as files on the physical machine disk.
Sample Data
{
"tracer_data": {
"content": "/proc/net/bonding/bond0\nEthernet Channel Bonding Driver: v4.18.0...\nBonding Mode: IEEE 802.3ad Dynamic link aggregation\nMII Status: down\n..."
}
}
Fields
- content: Complete bonding interface status information (multi-line text containing LACP negotiation details for all slaves, equivalent to the
/proc/net/bonding/bondXfile content)
11. netdev_txqueue_timeout
Description Detects NIC transmit queue timeout (TX queue timeout) events. Records the queue index, device name, and driver name where the timeout occurred, used to identify hardware failures on the NIC transmit path.
Data Storage Automatically stored in Elasticsearch or as files on the physical machine disk.
Sample Data
{
"tracer_data": {
"queue_index": 3,
"device_name": "eth0",
"driver_name": "ixgbe"
}
}
Fields
- queue_index: Index of the transmit queue where the timeout occurred
- device_name: Network device name
- driver_name: NIC driver name
⚙️ How It Works
Architecture
HUATUO’s anomalous event observation is built on eBPF technology. Event data is collected in kernel space with minimal performance overhead, and processed by user-space daemons for formatting, filtering, container association, and persistent storage.
graph TB
subgraph "Linux Kernel"
direction TB
K1["kprobe hooks\n(softirq_tracing / softlockup / hungtask\n oom / memory_reclaim_events / dropwatch\n net_rx_latency / netdev_txqueue_timeout)"]
K2["tracepoint hooks\n(ras: MCE / EDAC / AER / ACPI)"]
K3["netlink subscription\n(netdev_events: RTM_NEWLINK)"]
K4["kprobe hooks\n(netdev_bonding_lacp: 802.3ad)"]
PEB["Perf Event Ring Buffer\n(8192 pages)"]
end
subgraph "HUATUO User Space"
direction TB
EH["Go event handler goroutines\n(one per event type)"]
CF["Filters\n(threshold / noise reduction / known-issue filtering)"]
CM["Container association\n(CSS → ContainerID\n NetNS → ContainerID)"]
end
subgraph "Storage"
ES["Elasticsearch"]
DISK["Local disk files"]
end
K1 --> PEB
K2 --> PEB
K4 --> PEB
PEB --> EH
K3 --> EH
EH --> CF
CF --> CM
CM --> ES
CM --> DISK
Event Processing Flow
sequenceDiagram
participant K as Linux Kernel
participant B as eBPF Program
participant P as Perf Event Buffer
participant H as Go Event Handler
participant F as Filter
participant S as Storage
K->>B: kprobe / tracepoint fires
B->>B: Collect event context<br/>(process info / kernel stack / network context)
B->>P: Write to perf event ring buffer
H->>P: Read event data (blocking)
H->>F: Format and apply filters<br/>(threshold / noise / known issues)
F->>H: Events that passed filtering
H->>H: Associate container information<br/>(CSS / NetNS mapping)
H->>S: Persist to storage<br/>(Elasticsearch / local files)

5.3 - AutoTracing
📖 Overview
AutoTracing is an event-driven automatic diagnosis mechanism. When a host or container shows performance anomalies — such as CPU spikes, accumulation of D-state processes, saturated disk IO, or sudden memory allocation — the system triggers on-site data collection automatically based on preset thresholds, with no manual intervention required.
Collected artifacts include eBPF flame graphs (system-wide or container-scoped CPU call stack samples via perf), D-state process kernel call stacks, disk IO call stacks, and process memory usage rankings. Each event type has a built-in cooldown period (30 minutes by default) to prevent redundant data from continuous triggers.
Five event types are supported: cpusys (host CPU sys spike), cpuidle (container CPU usage spike), dload (container D-state load spike), iotracing (disk IO anomaly), and memburst (memory burst allocation).
🎯 Use Cases
CPU Hotspot Analysis for AI Training Jobs: In GPU training clusters, intermittent training stalls are often caused by sudden increases in kernel-mode CPU usage (cpusys). When sys utilization exceeds the threshold, AutoTracing immediately triggers a system-wide perf flame graph collection, persisting kernel call stack hotspots as structured flame graph data (flamedata) for offline analysis after the anomaly has passed.
Container CPU Jitter Analysis in Kubernetes: In microservice architectures, brief container CPU spikes (cpuidle) may cause response timeouts, but the issue often recovers before alert responders can act. When container CPU exceeds the threshold, AutoTracing triggers container-scoped perf sampling and generates a flame graph scoped to the container’s cgroup, identifying hotspot functions and reducing time spent on log-based investigation.
D-State Process Accumulation in Cloud-Native Environments: Under high IO load or storage jitter, containers may accumulate large numbers of D-state (uninterruptible sleep) processes, causing system stalls. The dload event applies an exponential weighted moving average (EMA) to the container’s uninterruptible process load. When the EMA exceeds the threshold, kernel call stacks are collected for all D-state processes inside the container and on the host, pinpointing the blocking root cause.
Disk IO Bottleneck Root Cause Analysis: In data-intensive or log-heavy workloads, saturated disk IO utilization or write bandwidth causes application request backlog. iotracing continuously polls /proc/diskstats and triggers when any IO metric exceeds its threshold for two consecutive samples. It then collects a list of high-IO processes (with per-process read/write byte counts and open file details) and kernel call stacks of processes waiting in IO scheduling, narrowing down the processes responsible for high disk IO consumption.
🚀 Usage
Configuration
All events provide default values and work without configuration:
| Parameter | Default | Description |
|---|---|---|
cpuidle.user_threshold |
75 (%) |
Container CPU user utilization trigger threshold |
cpuidle.sys_threshold |
45 (%) |
Container CPU sys utilization trigger threshold |
cpuidle.usage_threshold |
90 (%) |
Container total CPU utilization trigger threshold |
cpuidle.delta_user_threshold |
45 (%) |
Container CPU user utilization delta trigger threshold |
cpuidle.delta_sys_threshold |
20 (%) |
Container CPU sys utilization delta trigger threshold |
cpuidle.delta_usage_threshold |
55 (%) |
Container total CPU utilization delta trigger threshold |
cpuidle.interval |
10 (s) |
Detection interval |
cpuidle.interval_tracing |
1800 (s) |
Per-container cooldown period between triggers |
cpuidle.run_tracing_tool_timeout |
10 (s) |
perf flame graph collection timeout |
cpusys.sys_threshold |
45 (%) |
Host CPU sys utilization trigger threshold |
cpusys.delta_sys_threshold |
20 (%) |
Host CPU sys utilization delta trigger threshold |
cpusys.interval |
10 (s) |
Detection interval |
cpusys.run_tracing_tool_timeout |
10 (s) |
perf flame graph collection timeout |
dload.threshold_load |
5 |
Container D-state process load EMA trigger threshold |
dload.interval |
10 (s) |
Detection interval |
dload.interval_tracing |
1800 (s) |
Per-container cooldown period between triggers |
iotracing.rbps_threshold |
2000 (MB/s) |
Disk read throughput trigger threshold |
iotracing.wbps_threshold |
1500 (MB/s) |
Disk write throughput trigger threshold |
iotracing.util_threshold |
90 (%) |
Disk IO utilization trigger threshold |
iotracing.await_threshold |
100 (ms) |
Disk IO average wait time trigger threshold |
iotracing.run_tracing_tool_timeout |
10 (s) |
IO call stack collection timeout |
iotracing.max_proc_dump |
10 |
Maximum number of high-IO processes to collect |
iotracing.max_files_per_proc_dump |
5 |
Maximum open files to collect per process |
memburst.delta_memory_burst |
100 (%) |
Anonymous memory growth rate threshold relative to the oldest sample in the sliding window (100% means ≥ 2× triggers) |
memburst.delta_anon_threshold |
70 (%) |
Anonymous memory as a percentage of total host memory threshold |
memburst.interval |
10 (s) |
Detection interval |
memburst.interval_tracing |
1800 (s) |
Cooldown period between triggers |
memburst.sliding_window_length |
60 |
Sliding window sample count (corresponding to 600 seconds of history) |
memburst.dump_process_max_num |
10 |
Maximum number of top memory-consuming processes to collect |
Event List
| Event Name (tracer_name) | Target | Trigger Condition | Typical Scenario |
|---|---|---|---|
cpusys |
Host | sys > 45% or delta_sys > 20% | Kernel-mode CPU spike, syscall hotspot |
cpuidle |
Container | (user>75% and delta_user>45%) or (sys>45% and delta_sys>20%) or (total>90% and delta_total>55%) | Container CPU spike, hotspot function analysis |
dload |
Container | D-state process load EMA > 5 | D-state process accumulation, IO blocking |
iotracing |
Host | Any IO metric exceeds threshold for two consecutive samples | Saturated disk IO, high IO wait latency |
memburst |
Host | Anonymous memory ≥ 2× oldest window sample and ≥ 70% of total memory | Memory burst allocation, OOM precursor |
Fields
All event records include the following common fields:
- hostname: Physical host hostname
- region: Availability zone of the physical host
- uploaded_time: Data upload timestamp
- container_id: Container ID if the event is associated with a container
- container_hostname: Container hostname if the event is associated with a container
- container_host_namespace: Kubernetes namespace of the container
- container_type: Container type (e.g.,
normal,sidecar) - container_qos: Container QoS level
- tracer_name: Event name (e.g.,
cpusys,memburst) - tracer_id: Tracing session ID
- tracer_time: Time when the tracing was triggered
- tracer_type: Trigger type (manual or automatic)
- tracer_data: Event-specific private data (see individual event descriptions below)
1. cpusys
Description Periodically reads /proc/stat to calculate host CPU sys utilization and the delta between consecutive samples. When sys utilization exceeds the threshold (default 45%) or the delta exceeds its threshold (default 20%), a system-wide perf sampling run is triggered to generate a full-host CPU flame graph.
Storage Event data is automatically stored in Elasticsearch or a local disk file.
Sample Data
{
"tracer_name": "cpusys",
"tracer_data": {
"now_sys": 52,
"sys_threshold": 45,
"deltasys": 25,
"deltasys_threshold": 20,
"flamedata": [
{"level": 0, "value": 1000, "self": 0, "label": "all"},
{"level": 1, "value": 350, "self": 350, "label": "do_syscall_64"}
]
}
}
Field Descriptions
- now_sys: Host CPU sys utilization at trigger time (%)
- sys_threshold: sys utilization trigger threshold (%)
- deltasys: sys utilization delta between consecutive samples (%)
- deltasys_threshold: sys delta trigger threshold (%)
- flamedata: Flame graph frame data from perf sampling. Each frame contains:
- level: Call stack depth level
- value: Sample count for this frame including descendant frames
- self: Sample count for this frame excluding descendant frames
- label: Function or process name label
2. cpuidle
Description Periodically reads container cgroup CPU statistics to calculate container CPU user, sys, and total utilization along with their inter-sample deltas. A trigger fires if any of the following conditions holds: (user>75% and delta_user>45%), or (sys>45% and delta_sys>20%), or (total>90% and delta_total>55%). Container-scoped perf sampling is then run to generate a flame graph. A 30-minute per-container cooldown prevents repeated triggers. Specific containers can be excluded via the filter configuration.
Storage Event data is automatically stored in Elasticsearch or a local disk file.
Sample Data
{
"tracer_name": "cpuidle",
"tracer_data": {
"user": 80,
"user_threshold": 75,
"deltauser": 48,
"deltauser_threshold": 45,
"sys": 12,
"sys_threshold": 45,
"deltasys": 5,
"deltasys_threshold": 20,
"usage": 92,
"usage_threshold": 90,
"deltausage": 53,
"deltausage_threshold": 55,
"flamedata": [
{"level": 0, "value": 1000, "self": 0, "label": "all"},
{"level": 1, "value": 800, "self": 800, "label": "java/com.example.App.main"}
]
}
}
Field Descriptions
- user / user_threshold: Container CPU user utilization at trigger time (%) and its threshold
- deltauser / deltauser_threshold: User utilization inter-sample delta (%) and its threshold
- sys / sys_threshold: Container CPU sys utilization at trigger time (%) and its threshold
- deltasys / deltasys_threshold: Sys utilization inter-sample delta (%) and its threshold
- usage / usage_threshold: Container total CPU utilization at trigger time (%) and its threshold
- deltausage / deltausage_threshold: Total utilization inter-sample delta (%) and its threshold
- flamedata: Container-scoped perf flame graph frame data; field meanings same as
cpusys
3. dload
Description Reads container process states via netlink and cgroup, then computes an exponential weighted moving average (EMA) of the load contribution from uninterruptible (D-state) processes per container. When the EMA exceeds the threshold (default 5), kernel call stacks are collected for all D-state processes inside the container and on the host. Known-issue filtering (issues_list) reduces false positives. A 30-minute per-container cooldown applies.
Storage Event data is automatically stored in Elasticsearch or a local disk file.
Sample Data
{
"tracer_name": "dload",
"tracer_data": {
"threshold": 5,
"nr_sleeping": 120,
"nr_running": 4,
"nr_stopped": 0,
"nr_uninterruptible": 8,
"nr_iowait": 3,
"load_avg": 7.23,
"dload_avg": 6.81,
"known_issue": "",
"stack": "task:java state:D stack: 0 pid: 12345 tgid: 12345 ...\n io_schedule+0x18/0x40\n ext4_file_write_iter+0x..."
}
}
Field Descriptions
- threshold: D-state load EMA trigger threshold
- nr_sleeping: Number of sleeping processes in the container
- nr_running: Number of running processes in the container
- nr_stopped: Number of stopped processes in the container
- nr_uninterruptible: Number of uninterruptible (D-state) processes in the container
- nr_iowait: Number of IO-waiting processes in the container
- load_avg: Container load average at trigger time
- dload_avg: Container D-state load EMA value at trigger time
- known_issue: Matched known issue description (empty if none matched)
- stack: Kernel call stacks of D-state processes (multi-process, multi-line text)
4. iotracing
Description Polls /proc/diskstats at 5-second intervals to calculate per-disk read/write throughput, IO utilization, and IO wait time. md devices are excluded automatically. A trigger fires when any metric exceeds its threshold for two consecutive samples. On trigger, the system collects a list of high-IO processes (with per-process read/write byte counts and open file details) and kernel call stacks of processes waiting in IO scheduling.
Storage Event data is automatically stored in Elasticsearch or a local disk file.
Sample Data
{
"tracer_name": "iotracing",
"tracer_data": {
"reason_snapshot": {
"type": "ioutil",
"device": "sda",
"iostatus": {
"read_bps": 120,
"read_iops": 450,
"read_await": 12,
"write_bps": 2100,
"write_iops": 890,
"write_await": 145,
"io_util": 95,
"queue_size": 32
}
},
"process_io_data": [
{
"pid": 12345,
"comm": "java",
"container_hostname": "app-pod-xxx",
"fs_read": 0,
"fs_write": 52428800,
"disk_read": 0,
"disk_write": 49152000,
"file_stat": ["/data/logs/app.log"],
"file_count": 1
}
],
"timeout_io_stack": [
{
"pid": 12345,
"comm": "java",
"container_hostname": "app-pod-xxx",
"latency_us": 250000,
"stack": {
"back_trace": [
"io_schedule+0x18/0x40",
"ext4_file_write_iter+0x2a0/0x4c0"
]
}
}
]
}
}
Field Descriptions
- reason_snapshot: Snapshot of the condition that triggered IO collection
- type: Trigger type (
ioutilIO utilization /read_bpsread throughput /write_bpswrite throughput /read_awaitread wait time /write_awaitwrite wait time) - device: Name of the disk device that exceeded the threshold
- iostatus: Disk IO metric snapshot at trigger time (
read_bps/write_bpsin MB/s,read_await/write_awaitin ms,io_utilin %,queue_sizeis queue depth)
- type: Trigger type (
- process_io_data: List of high-IO processes. Each record contains:
- pid / comm: Process PID and name
- container_hostname: Container hostname of the process (empty for host processes)
- fs_read / fs_write: Bytes read/written at the filesystem layer
- disk_read / disk_write: Bytes actually read/written at the disk layer
- file_stat: List of file paths currently open by the process
- file_count: Total number of files open by the process
- timeout_io_stack: Call stacks of processes waiting in IO scheduling. Each record contains:
- pid / comm: Process PID and name
- container_hostname: Container hostname of the process
- latency_us: IO wait duration (microseconds)
- stack.back_trace: List of kernel call stack frames
5. memburst
Description Periodically samples host anonymous memory usage and maintains a sliding window of 60 samples (corresponding to 600 seconds). A trigger fires when current anonymous memory is ≥ 2× the oldest sample in the window and anonymous memory accounts for ≥ 70% of total host memory. On trigger, the top N processes by memory consumption (default 10) are collected, recording their PID, process name, and RSS memory size. A 30-minute cooldown applies.
Storage Event data is automatically stored in Elasticsearch or a local disk file.
Sample Data
{
"tracer_name": "memburst",
"tracer_data": {
"top_memory_usage": [
{
"pid": 3456,
"process_name": "java",
"memory_size": 8589934592
},
{
"pid": 3789,
"process_name": "python3",
"memory_size": 2147483648
}
]
}
}
Field Descriptions
- top_memory_usage: List of top memory-consuming processes sorted by RSS in descending order. Each record contains:
- pid: Process PID
- process_name: Process name
- memory_size: Process RSS memory usage (bytes)
⚙️ Principle
Architecture
AutoTracing is built on periodic polling, combined with eBPF call stack collection and perf flame graph generation, to collect anomaly diagnostic data at the kernel level with low overhead.
graph TB
subgraph "Data Sources"
P1["/proc/stat\n(Host CPU utilization)"]
P2["cgroup CPU stats\n(Container CPU utilization)"]
P3["netlink / cgroup\n(Container process states / load average)"]
P4["/proc/diskstats\n(Disk IO metrics)"]
P5["/proc/meminfo\n+ cgroup memory stats"]
end
subgraph "HUATUO AutoTracing"
DT["Threshold Detection\n(sliding window / EMA / two consecutive breaches)"]
BO["Cooldown\n(30-minute backoff)"]
PERF["perf Flame Graph\n(system-wide / container-scoped)"]
BPF["eBPF kprobe\n(IO scheduling latency tracing)"]
CM["Container Correlation\n(cgroup → ContainerID)"]
end
subgraph "Storage"
ES["Elasticsearch"]
DISK["Local Disk File"]
end
P1 --> DT
P2 --> DT
P3 --> DT
P4 --> DT
P5 --> DT
DT --> BO
BO --> PERF
BO --> BPF
PERF --> CM
BPF --> CM
CM --> ES
CM --> DISK
Event Processing Flow
sequenceDiagram
participant M as Periodic Metric Collection
participant D as Threshold Detector
participant B as Cooldown (backoff)
participant C as On-site Data Collector
participant S as Storage
M->>D: Push metrics (every 10s)
D->>D: Evaluate threshold (sliding window / EMA / consecutive)
alt Threshold exceeded
D->>B: Check cooldown state
alt Trigger allowed
B->>C: Trigger collection<br/>(perf flame graph / D-state stacks / IO process list)
C->>C: Correlate container info (cgroup → ContainerID)
C->>S: Persist data (Elasticsearch / local file)
else In cooldown
B-->>D: Skip this trigger
end
end
5.4 - Continuous Profiling
Overview
Continuous Profiling performs long-running, continuous performance sampling of the operating system and applications, covering CPU, memory, and lock profiles. It produces standard pprof flame-graph data, persists samples to Elasticsearch, and supports aggregated viewing over arbitrary time windows in Grafana — providing a data foundation for capacity planning, performance regression analysis, and post-mortem diagnosis.
Architecture
Continuous Profiling is built on three cooperating components:
| Component | Role | Description |
|---|---|---|
| huatuo-apiserver | Control plane | Receives profiling jobs, dispatches them to target nodes, and exposes a Pyroscope-compatible flame-graph query API |
| huatuo-bamai | Data plane | Runs collection on the target node, sampling call stacks via eBPF (C/C++/Go) or third-party tools (Java/Python) |
| Grafana | Visualization | Connects directly to apiserver through the pyroscope datasource plugin to render flame graphs |
Supported languages and underlying implementations:
| Language | Profile types | Implementation |
|---|---|---|
| C / C++ / Go | CPU / memory / lock | eBPF (perf_event + stack maps) |
| Java | CPU / memory / lock | async-profiler |
| Python | CPU / memory | py-spy / memray |
Profile type identifiers (used in Grafana queries):
| Type | profile_type |
|---|---|
| CPU | process_cpu:cpu:nanoseconds:cpu:nanoseconds |
| Memory | memory:alloc_space:bytes:space:bytes |
| Lock | process_lock:lock:count:lock:countprocess_lock:lock:nanoseconds:lock:nanoseconds |
Running
The simplest way is to bring up Elasticsearch, Prometheus, Grafana, huatuo-apiserver, and huatuo-bamai together with Docker Compose:
$ docker compose --project-directory ./build/docker up
Component addresses after startup:
| Component | Address |
|---|---|
| huatuo-apiserver | http://127.0.0.1:12740 |
| huatuo-bamai metrics | http://127.0.0.1:19704/metrics |
| Grafana | http://localhost:3000 (admin / admin) |
| Elasticsearch | http://127.0.0.1:9200 |
Profiling-related configuration lives in the [Profiling] section of huatuo-apiserver.conf:
| Parameter | Default | Description |
|---|---|---|
CPUProfilingInterval |
10 | Single CPU sampling duration (seconds) |
MemoryProfilingInterval |
10 | Single memory sampling duration (seconds) |
CPUSingleTraceTimeout |
20 | Single CPU sampling timeout (seconds) |
MemorySingleTraceTimeout |
20 | Single memory sampling timeout (seconds) |
ThirdPartyToolLimit |
10 | Max concurrent third-party tools (async-profiler, etc.) |
FlameGraphBaseURL |
http://localhost:8006/d |
Flame-graph dashboard base URL, used to build task result links |
To make the
results.urlreturned by a task point directly at Grafana, setFlameGraphBaseURLto the actual Grafana address (e.g.http://localhost:3000/d).
Apiserver API calls require an Authorization request header carrying the user ID (configured under [[Auth.users]] in huatuo-apiserver.conf).
The default conf ships with no users configured, so the auth middleware is disabled and
Authorizationcan be any non-empty value. In production, always configure real users under[[Auth.users]]and replace<user-id>with the actual ID.
Collection: Host CPU Example
The following starts a CPU profile on a host. Host-level collection omits the container field; target_process_language is set to go (or c/c++) to trigger the eBPF native profiler:
$ curl -X POST http://127.0.0.1:12740/v1/profiles \
-H "Content-Type: application/json" \
-H "Authorization: <user-id>" \
-d '{
"type": "cpu",
"target_process_language": "go",
"hostname": "<target-host>",
"duration": 600
}'
Request fields:
| Field | Description |
|---|---|
type |
Profile type: cpu / memory |
target_process_language |
Target language: go, c, c++, java, python |
hostname |
Required. Target host name; apiserver dispatches the job to the huatuo-bamai agent at http://{hostname}:19704 (must match the hostname reported by the agent) |
duration |
Total profiling duration (seconds); the agent samples periodically at CPUProfilingInterval |
container |
Container hostname for container-level collection; leave empty for host-level |
target_exec_path |
Optional, filter target processes by executable path |
Response returns the task ID:
{ "id": "<task-id>" }
Collection flow:
- apiserver creates the job and dispatches it to the huatuo-bamai agent on the target host.
- huatuo-bamai loads an eBPF program (
perf_event_sw_cpu_clock) and samples kernel and user stacks at the default 99 Hz. - Samples are symbolized, converted to pprof format, and written to Elasticsearch (the index name is the
[ElasticSearch].Indexsetting inhuatuo-apiserver.conf, defaulthuatuo_bamai).
Query job status and stop a job:
# Query job status
$ curl -H "Authorization: <user-id>" \
http://127.0.0.1:12740/v1/profiles/<task-id>
# Stop a job
$ curl -X PATCH http://127.0.0.1:12740/v1/profiles/<task-id> \
-H "Content-Type: application/json" \
-H "Authorization: <user-id>" \
-d '{"status":"stopped"}'
On completion, the results.url field in the status response carries a flame-graph link built from FlameGraphBaseURL.
Viewing
Flame graphs are viewed through pre-provisioned Grafana dashboards that load automatically with Docker Compose:
| Dashboard | UID | Scope |
|---|---|---|
| Continuous Profiling(host) | continuous-profiling-host |
Host |
| Continuous Profiling(container) | continuous-profiling-container |
Container |
Open http://localhost:3000/d/continuous-profiling-host, select hostname and type (profile_type) to view the aggregated flame graph. The time-series panel at the top shows the sample distribution, and the flame-graph panel below supports aggregated viewing over a selectable time range.
How it works: Grafana forwards flame-graph requests to the apiserver’s
/v1/profiles/flamegraph/path via thegrafana-pyroscope-datasourceplugin. The apiserver implements the Pyroscope Querier protocol (SelectMergeStacktraces, etc.), retrieving pprof data from Elasticsearch, merging it, and returning the result.
5.5 - Hardware Events
Overview
HUATUO monitors Linux kernel hardware error events with zero instrumentation overhead and minimal runtime cost. Structured fault records are persisted to storage and exposed as Prometheus counters for use by alerting and visualization systems.
Use Cases
-
General-Purpose Computing
In large-scale server clusters, memory ECC correctable errors (CE) are common low-severity fault signals. A single CE is automatically corrected by hardware. If the CE rate on a given DIMM rises persistently, however, it indicates impending memory failure. HUATUO detects such events in real time via EDAC/MCE tracepoints, enabling operations teams to perform preventive replacements before complete memory failure and unplanned downtime occur.
-
AI Computing
AI training workloads require high hardware reliability. A single faulty PCIe device can cause an entire training job to fail. HUATUO supports PCIe AER event monitoring and reports link-layer errors on GPUs, NVLink bridges, and RDMA NICs (such as InfiniBand HCAs) — including Data Link Protocol Errors and ECRC Errors — in real time. This data provides hardware health status to AI cluster schedulers, supporting rapid fault node isolation and workload migration.
-
Storage Services
Storage servers typically host large numbers of PCIe NVMe SSDs and HBA cards. PCIe AER errors such as Completion Timeout and Malformed TLP are early indicators of storage device performance degradation or drive dropout. HUATUO monitoring data can be correlated with storage I/O latency metrics to support root cause analysis.
-
Security and Compliance
Industries with strict compliance requirements — such as finance and government — must maintain a complete history of all hardware faults. Structured event records (including timestamps, device identifiers, error types, and raw register values) can serve directly as compliance evidence for hardware health logs.
How It Works
HUATUO observes the kernel’s MCE, EDAC, ACPI GHES, and PCIe AER subsystems via eBPF. When an eBPF tracepoint fires, the raw event is written to a BPF Perf Event Buffer. A user-space process reads the event, parses the struct fields, generates a structured record, and persists it locally or to a remote store. The overall architecture is shown below:
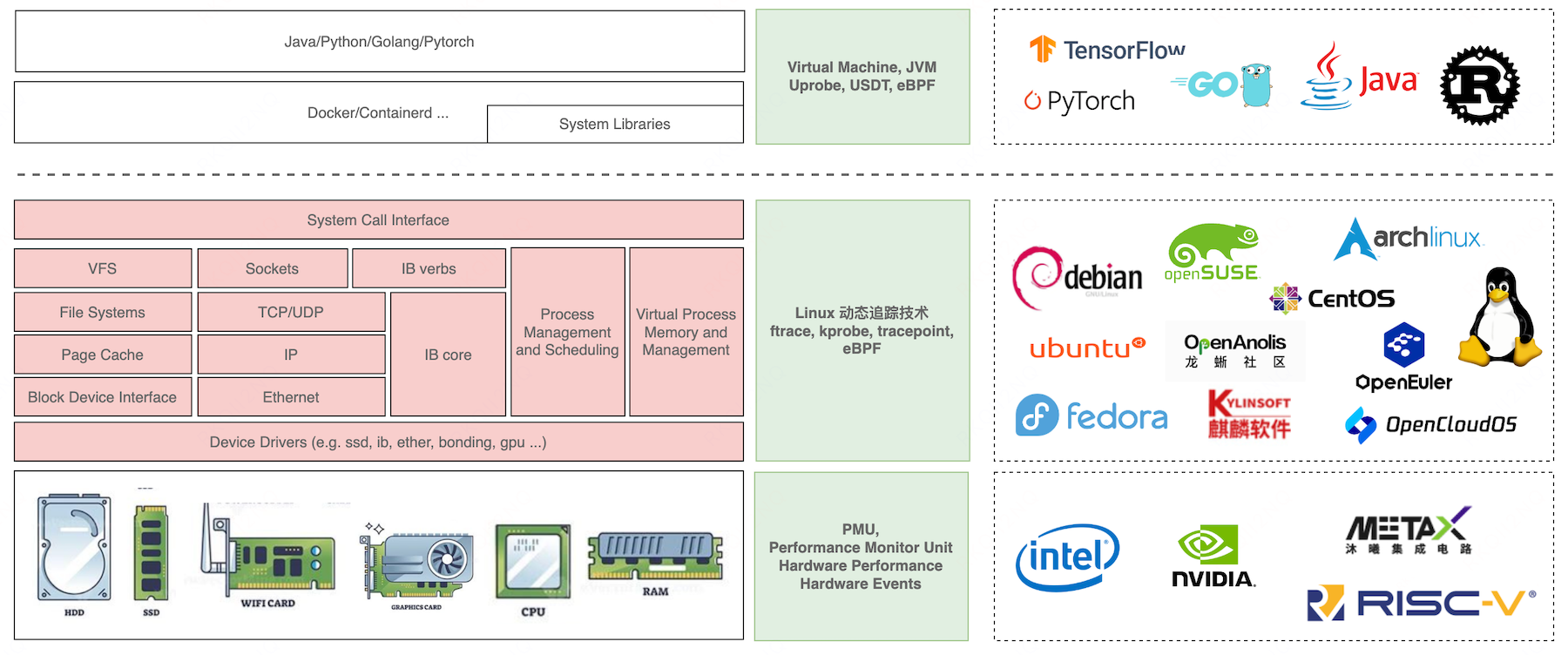
RAS Architecture
The Linux kernel’s RAS framework consists of several loosely coupled subsystems. Together, they cover the full hardware fault spectrum — from CPU internal errors to PCIe link errors.
graph TB
subgraph HW["Hardware Layer"]
CPU["CPU\nx86 / x86-64"]
MEM["Memory\nDDR4/DDR5 DIMM ECC"]
Platform["Platform Hardware\nSoC / PCH"]
PCIeDev["PCIe Devices\nGPU / NVMe / HCA / FPGA"]
end
subgraph FW["Firmware Layer"]
BIOS["BIOS / UEFI\nCPER Buffer (APEI)"]
end
subgraph Kernel["Linux Kernel RAS Subsystems"]
MCE["MCE Subsystem\narch/x86/kernel/cpu/mce"]
EDAC["EDAC Subsystem\ndrivers/edac"]
GHES["ACPI GHES Subsystem\ndrivers/acpi/apei"]
AER["PCIe AER Subsystem\ndrivers/pci/pcie/aer"]
end
subgraph TP["Kernel Tracepoints"]
TP1["tracepoint/mce/mce_record"]
TP2["tracepoint/ras/mc_event"]
TP3["tracepoint/ras/non_standard_event"]
TP4["tracepoint/ras/aer_event"]
end
CPU -->|"MCE Exception (#MC) + THR Interrupt"| MCE
MEM -->|ECC Error| EDAC
Platform -->|APEI Error Record| BIOS
BIOS -->|CPER Buffer| GHES
PCIeDev -->|AER Interrupt| AER
MCE --> TP1
EDAC --> TP2
GHES --> TP3
AER --> TP4
-
MCE
MCE (Machine Check Architecture) is a hardware fault-tolerance mechanism built into the processor, defined by Intel and AMD in their respective architecture specifications. The processor contains a set of Machine Check Banks, each corresponding to a class of hardware resource (e.g., L1 cache, L2 cache, memory controller, TLB). When a hardware error is detected, the MSRs of the corresponding bank (
MCi_STATUS,MCi_ADDR,MCi_MISC) are populated with error information, and an MCE exception is raised. -
MCE THR
MCE supports a threshold interrupt mechanism. When the count of a given class of correctable errors exceeds a configured threshold, a dedicated APIC interrupt (THR) is triggered instead of escalating to a full MCE exception. This allows the operating system to issue an early alert when the error rate rises abnormally, rather than waiting until the error becomes uncorrectable.
-
EDAC
EDAC (Error Detection And Correction) is the Linux kernel subsystem dedicated to handling memory and hardware ECC errors. Its stated goal is “to detect and report errors occurring in the computer hardware running under Linux.” EDAC drivers communicate directly with the memory controller and parse the physical location of ECC errors — including memory controller index, channel, slot, and row/column address.
-
ACPI GHES
ACPI GHES (Generic Hardware Error Source) is a platform-agnostic hardware error reporting mechanism defined by the BIOS/UEFI through the APEI (ACPI Platform Error Interface) specification. The BIOS firmware writes hardware errors that cannot be handled by a specific driver — such as SoC-internal errors or platform-specific memory errors — into CPER (Common Platform Error Record) buffers described in the GHES descriptor. The Linux kernel reads these CPER records and reports the “non-standard” error sections that cannot be parsed by a standard subsystem.
-
PCIe AER
PCIe AER (Advanced Error Reporting) is an error reporting mechanism defined in the PCIe specification. It enables PCIe devices to report link-layer and transaction-layer errors to the operating system with precision.
Metrics Reference
-
RAS Metrics
# HELP huatuo_bamai_ras_hw_total total RAS hardware error events by source type # TYPE huatuo_bamai_ras_hw_total counter huatuo_bamai_ras_hw_total{host="hostname",region="dev",type="acpi"} 0 huatuo_bamai_ras_hw_total{host="hostname",region="dev",type="aer"} 0 huatuo_bamai_ras_hw_total{host="hostname",region="dev",type="edac"} 0 huatuo_bamai_ras_hw_total{host="hostname",region="dev",type="mce"} 0 huatuo_bamai_ras_hw_total{host="hostname",region="dev",type="thr"} 0 -
NIC Packet Drop
huatuo_bamai_netdev_hw_rx_dropped_total{host="hostname",region="dev",device="eth0",driver="ixgbe"} 0 -
RDMA PFC
# HELP huatuo_bamai_netdev_dcb_pfc_received_total count of the received pfc frames # TYPE huatuo_bamai_netdev_dcb_pfc_received_total counter huatuo_bamai_netdev_dcb_pfc_received_total{device="enp6s0f0np0",host="hostname",prio="0",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_received_total{device="enp6s0f0np0",host="hostname",prio="1",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_received_total{device="enp6s0f0np0",host="hostname",prio="2",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_received_total{device="enp6s0f0np0",host="hostname",prio="3",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_received_total{device="enp6s0f0np0",host="hostname",prio="4",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_received_total{device="enp6s0f0np0",host="hostname",prio="5",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_received_total{device="enp6s0f0np0",host="hostname",prio="6",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_received_total{device="enp6s0f0np0",host="hostname",prio="7",region="dev"} 0 # HELP huatuo_bamai_netdev_dcb_pfc_send_total count of the sent pfc frames # TYPE huatuo_bamai_netdev_dcb_pfc_send_total counter huatuo_bamai_netdev_dcb_pfc_send_total{device="enp6s0f0np0",host="hostname",prio="0",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_send_total{device="enp6s0f0np0",host="hostname",prio="1",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_send_total{device="enp6s0f0np0",host="hostname",prio="2",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_send_total{device="enp6s0f0np0",host="hostname",prio="3",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_send_total{device="enp6s0f0np0",host="hostname",prio="4",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_send_total{device="enp6s0f0np0",host="hostname",prio="5",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_send_total{device="enp6s0f0np0",host="hostname",prio="6",region="dev"} 0 huatuo_bamai_netdev_dcb_pfc_send_total{device="enp6s0f0np0",host="hostname",prio="7",region="dev"} 0 -
Storage
Every hardware error event is persisted in structured form — either to the local
huatuo-localdirectory or to a remote store such as Elasticsearch or OpenSearch. All records share the following common fields:{ "hostname": "hostname", "region": "dev", "uploaded_time": "2026-03-05T18:28:39.153438921+08:00", "time": "2026-03-05 18:28:39.153 +0800", "tracer_name": "netdev_event", "tracer_time": "2026-03-05 18:28:39.153 +0800", "tracer_type": "auto", "tracer_data": { "ifname": "eth0", "index": 2, "linkstatus": "linkstatus_admindown", "mac": "5c:6f:11:11:11:11", "start": false } }The
linkstatusfield takes the following values:linkstatus_adminup— brought up by an administrator, e.g.,ip link set dev eth0 uplinkstatus_admindown— brought down by an administrator, e.g.,ip link set dev eth0 downlinkstatus_carrierup— physical link restoredlinkstatus_carrierdown— physical link failure
{ "hostname": "localhost", "region": "xxx", "uploaded_time": "2026-05-11T16:58:47.328548319+08:00", "time": "2026-05-11 16:58:47.328 +0800", "tracer_name": "ras", "tracer_time": "2026-05-11 16:58:47.328 +0800", "tracer_type": "auto", "tracer_data": { "dev": "MEM", "event": "EDAC", "type": "Corrected", "timestamp": 537792166031, "info": "{\"err_count\":0,\"err_type\":\"Corrected\",\"err_msg\":\"memory read error\",\"label\":\"CPU_SrcID#0_Ha#0_Chan#0_DIMM#0\",\"mc_index\":0,\"top_layer\":0,\"mid_layer\":0,\"low_layer\":-1,\"addr\":7860269056,\"grain\":128,\"syndrome\":0,\"driver\":\" area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:1 rank:0\"}" } }Field Description DeviceIdentifier of the hardware component where the error occurred (e.g., CPU/MEM,MEM,ACPI,PCIe 0000:01:00.0)EventEvent subtype ( MCE,EDAC,APIC,AER)ErrTypeError severity level (see table below) TimestampTimestamp InfoDetailed fields for the specific event Error Type Description Typical Sources CorrectedAutomatically corrected by hardware; transparent to the OS MCE CE, EDAC CE, ACPI Sev=1, AER Severity=2 UncorrectedRecoverableNot corrected by hardware, but recoverable by system software MCE UE, EDAC UE, ACPI Sev=2, AER Severity=0 UncorrectedDeferredNot corrected by hardware; requires deferred handling MCE MCI_STATUS_DEFERRED, EDAC HW_EVENT_ERR_DEFERRED UncorrectedFatalFatal hardware error; requires immediate reboot EDAC FATAL, ACPI Sev=3, AER Severity=0 InfoError type for which the system is expected to log informational records EDAC HW_EVENT_ERR_INFO, ACPI Sev=0
Field Reference
-
MCE
Monitored components: CPU cores, L1/L2/L3 cache, TLB, memory controller (IMC), and interconnect buses (QPI/UPI/Infinity Fabric).
Field MSR Source Description mcg_cpu_capMCG_CAPMachine Check Global Capability Register. The lower 8 bits ( Count) indicate the number of MC Banks in the system.mcg_msr_statusMCG_STATUSMachine Check Global Status Register. banks_msr_statusMCi_STATUSBank Status Register (primary field). The lower 16 bits contain the MCA error code, classifying the error type (e.g., memory hierarchy error, bus error). The upper bits include control flags: UC(uncorrectable),EN(enabled),MISCV(MISC valid),ADDRV(ADDR valid), andPCC(processor context corrupt).banks_msr_addrMCi_ADDRPhysical memory address where the error occurred (valid only when MCi_STATUS.ADDRV=1). Used to identify the faulty DIMM or cache line.banks_msr_miscMCi_MISCSupplementary information register (valid only when MCi_STATUS.MISCV=1).mca_synd_msrMCA_SYNDSyndrome register (AMD-specific). mca_ipid_msrMCA_IPIDInstance ID register (AMD-specific). instr_pointerRIP register Instruction pointer at the time of the MCE (reliable only when MCG_STATUS.EIPV=1).tsc_timestampTSC CPU timestamp counter value at the time of the error (can be converted to absolute time using the kernel clock). walltimeKernel time Unix timestamp (in seconds) at the time of the error. cpu— Logical CPU number where the MCE occurred. cpuidCPUID CPUID value of the CPU where the MCE occurred (includes Family, Model, and Stepping). apicidAPIC ID APIC ID of the CPU where the MCE occurred (can be mapped to a physical core or hyperthread). socketid— CPU socket number (Socket ID). Used to identify physical CPUs in multi-socket servers. code_segCS register Code segment register value at the time of the MCE (used to determine privilege level). bank— Bank number (typically: Bank 0 = L1I, Bank 1 = L1D, Bank 2 = L2, Bank 4+ = memory controller; numbering varies by platform). cpuvendor— CPU vendor identifier: 0= Intel,1= Unknown,2= AMD. -
EDAC
Monitored components: memory ECC errors.
Field Description err_countCumulative error count for this event. err_typeError severity level. err_msgHuman-readable error description string (e.g., "CE memory read error on CPU#0Channel#0_DIMM#0 (channel:0 slot:0 page:0x12345 offset:0x0 grain:8 syndrome:0x0)").labelPhysical DIMM location label (e.g., "CPU_SrcID#0_Ha#0_Chan#0_DIMM#0"). Generated by the EDAC driver based on DIMM topology; maps directly to a physical memory slot in the system.mc_indexMemory controller index (0-based). Distinguishes between IMCs on servers with multiple memory controllers. top_layerTop-layer index in the memory hierarchy (typically the channel number; -1 indicates invalid). mid_layerMiddle-layer index in the memory hierarchy (typically the slot or rank number; -1 indicates invalid). low_layerBottom-layer index in the memory hierarchy (typically the bank or row number; -1 indicates invalid). addrPhysical memory address where the error occurred (64-bit unsigned integer; 0 indicates an invalid address). grainError granularity (grain size, in bytes). Represents the smallest memory unit that may be affected. Computed as 1 << GrainBits. For example,grain=8means the error is localized to an 8-byte unit (a cache line sub-block).syndromeECC syndrome value. driverEDAC driver name (e.g., "amd64_edac","sb_edac"). -
ACPI GHES
Monitored components: platform-specific hardware errors.
Field Description severityRaw ACPI/CPER error severity value. sec_typeError section type GUID (16 bytes, hexadecimal string). Defined by the UEFI specification and hardware vendors. Identifies the hardware category of the error record (e.g., memory error section, PCIe error section, ARM processor error section). fru_idFRU (Field Replaceable Unit) identifier GUID (16 bytes, hexadecimal string). Uniquely identifies the replaceable hardware component where the error occurred (e.g., a specific DIMM or PCIe card). fru_textHuman-readable FRU description string (e.g., "CPU0_DIMM_A1").data_lenRaw error data payload length (in bytes). raw_dataHexadecimal dump of raw error data (space-separated bytes). Used for in-depth diagnostics; must be interpreted with the relevant hardware vendor documentation. -
PCIe AER
Monitored devices include GPUs, NVMe SSDs, RDMA NICs/HCAs, FPGA accelerator cards, and PCIe switches.
Field Description dev_namePCIe device name (BDF format), e.g., "0000:03:00.0"(Domain:Bus:Device.Function).err_typeError severity level ( Corrected/Uncorrected/Fatal).err_reasonError reason description string. Decoded from the bits of the AER status register (see the tables below). tlp_headerTLP (Transaction Layer Packet) header quad-word that triggered the error (format: {dword0, dword1, dword2, dword3}, hexadecimal). The TLP header contains the transaction type, address, and requester ID — key data for root cause analysis. Displays"not available"whenTlpHeaderValid=0. -
PCIe Correctable Error Types
Bitmask Description 0x00000001Receiver Error. The physical layer received a data symbol that does not conform to the specification. Typically caused by signal integrity issues such as excessive cable length or impedance mismatch. 0x00000040Bad TLP. The LCRC (link-layer CRC) check on a TLP failed, indicating bit flips during transmission. The PCIe link layer automatically retransmits the TLP. 0x00000080Bad DLLP. A link-layer control packet (such as ACK/NAK or flow control update) failed its CRC check. 0x00000100Replay Number Rollover. The REPLAY_NUMfield tracks retransmit count. This error indicates too many retransmissions since the last ACK, typically signaling sustained poor link quality.0x00001000Replay Timer Timeout. The sender did not receive an ACK within the allowed time, triggering TLP retransmission. Persistent occurrence indicates abnormal link latency or insufficient receiver processing capacity. 0x00002000Advisory Non-Fatal Error. An uncorrectable error that software has downgraded to correctable (requires the ANFE feature in the AER capability). Commonly seen when an Unsupported Request Completion is received. 0x00004000Corrected Internal Error. An internal ECC or parity error that the device corrected autonomously. 0x00008000Header Log Overflow. The AER header log register is full. TLP headers for subsequent errors cannot be recorded, though errors are still counted. -
PCIe Uncorrectable Error Types
Bitmask Description 0x00000001Undefined. A reserved bit was set, typically indicating non-compliant firmware or hardware behavior. 0x00000010Data Link Protocol Error. A packet that violates the DLLP protocol specification was received. This is a severe link-layer fault. 0x00000020Surprise Down Error. The physical link disconnected without a Hot-Plug notification (e.g., due to unexpected power loss or poor contact). This is a high-severity error in hot-plug environments. 0x00001000Poisoned TLP. A TLP was received with the Error Poisoning (EP) bit set to 1, indicating that the upstream sender was aware of data corruption. This mechanism propagates and isolates errors to prevent silent data corruption. 0x00002000Flow Control Protocol Error. A packet that violates PCIe flow control credit rules was received. This is a severe protocol violation. 0x00004000Completion Timeout. The requester sent a non-posted transaction (e.g., Memory Read) but did not receive a Completion within the required timeout. Commonly caused by NVMe firmware issues, RDMA NIC driver bugs, or PCIe link interruptions. 0x00008000Completer Abort. The completer returned an explicit CA (Completer Abort) status, indicating that the request was rejected. 0x00010000Unexpected Completion. A Completion was received that could not be matched to any outstanding request (tag mismatch). Typically caused by device firmware bugs or data path errors. 0x00020000Receiver Overflow. The receiver’s flow control credits indicated available buffer space, but an overflow occurred. This is a severe flow control violation. 0x00040000Malformed TLP. The packet header contains fields that violate the specification (e.g., illegal length, reserved bits set, invalid address range). Typically indicates a severe firmware defect. 0x00080000ECRC Error. The ECRC check on the TLP trailer failed (requires ECRC support on both endpoints). Indicates data corruption across the entire transmission path, including internal PCIe switch fabric. A key metric in high-reliability environments. 0x00100000Unsupported Request. The completer returned a UR (Unsupported Request) status, indicating that the transaction type or address range is not supported by the device. 0x00200000ACS Violation. PCIe ACS (Access Control Services) prevents peer-to-peer DMA between PCIe devices from bypassing the IOMMU. This error indicates a data access that violates the ACS policy. Requires attention in virtualization security environments. 0x00400000Uncorrectable Internal Error. An internal ECC or parity error occurred that the device could not self-correct (e.g., SRAM double-bit error). Typically indicates hardware damage. 0x00800000MC Blocked TLP. A PCIe Multicast TLP was blocked by ACS or the Multicast control mechanism. 0x01000000AtomicOp Egress Blocked. An AtomicOp request (FetchAdd, Swap, or CAS) was blocked from egressing by ACS. Commonly seen in RDMA or GPU direct-connect configurations. 0x02000000TLP Prefix Blocked. A packet with an End-End TLP Prefix was blocked from forwarding by ACS or another mechanism.
Summary
Deploy HUATUO in production to enable hardware error monitoring and proactive operations.
6 - Best Practice
6.1 - Storage
📖 Overview
HUATUO supports persisting Linux kernel events collected by the Tracer and AutoTracing data to external storage backends. Both Elasticsearch and OpenSearch are supported.
After serialization to JSON, collected events are written concurrently to the local node directory (huatuo-local/) and the configured remote storage backend. The local directory retains a local copy of events; the remote backend provides durable storage and structured query capabilities.
This document covers configuration and verification for both Elasticsearch and OpenSearch. Examples use Docker deployments. In production, replace the addresses with your actual service endpoints — the configuration format is the same.
🎯 Use Cases
Kubernetes Cloud-Native Fault Tracing
In containerized environments, kernel events such as Pod OOM and node Hung Task are transient — logs are often purged shortly after the event occurs. By writing events to Elasticsearch or OpenSearch, operations teams can query the historical timeline of anomalies by time range and precisely identify the root cause of intermittent failures during post-incident reviews.
AI Compute Cluster Stability Auditing
During long-running GPU training workloads, the historical distribution of events such as ras hardware errors and iotracing I/O latency is critical for capacity planning and hardware health assessment. Persisting collected data enables aggregate queries to establish node stability baselines and supports proactive maintenance decisions.
Compliance and Event Retention
Security compliance standards require that system anomaly events be traceable. Writing HUATUO-captured kernel events to OpenSearch and configuring an index lifecycle policy satisfies compliance requirements for event retention periods and query capabilities.
Observability Platform Integration
Both Elasticsearch and OpenSearch provide native data source integrations with Grafana. Once HUATUO events are written to storage, you can build kernel event trend dashboards in Grafana, overlaid with application-layer metrics for historical analysis and alert review.
💎 Value
| Dimension | Local Storage Only | With External Storage Backend |
|---|---|---|
| Data Durability | Limited by node disk capacity; may be lost on restart | Persisted to distributed storage; supports long-term retention |
| Query Capability | No structured queries; relies on file search | Full-text search, field filtering, time-range aggregation |
| Visualization | Not supported | Direct integration with Grafana, Kibana, and similar platforms |
| Multi-node Aggregation | Data scattered across individual nodes | Centralized storage; supports cross-node queries |
| Compliance Retention | Difficult to meet retention requirements | Configurable index lifecycle policies; meets compliance retention requirements |
🚀 Usage
OpenSearch V2
1. Deploy OpenSearch
docker pull opensearchproject/opensearch:2.6.0
docker run -d --name opensearch --network host \
-e "discovery.type=single-node" \
opensearchproject/opensearch:2.6.0
2. Verify Service Status
curl -k -u admin:admin https://localhost:9200
Example response:
{
"name" : "22ca72df78c0",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "yxb3foceQVKzXXO6bHpPHQ",
"version" : {
"distribution" : "opensearch",
"number" : "2.6.0",
"build_type" : "tar",
"build_hash" : "7203a5af21a8a009aece1474446b437a3c674db6",
"build_date" : "2023-02-24T18:57:04.388618985Z",
"build_snapshot" : false,
"lucene_version" : "9.5.0",
"minimum_wire_compatibility_version" : "7.10.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "The OpenSearch Project: https://opensearch.org/"
}
If verification fails, check the container logs:
docker logs opensearch
3. Configure huatuo-bamai
Add the following configuration to huatuo-bamai.conf. The default username and password for the OpenSearch container image are both admin. For a full description of storage configuration options, refer to the Configuration Guide.
[Storage.ES]
Address = "https://127.0.0.1:9200"
Index = "huatuo_bamai"
Username = "admin"
Password = "admin"
4. Start huatuo-bamai
Use --config-dir to specify the directory containing the configuration file:
./_output/bin/huatuo-bamai --region dev --config-dir .
When files (e.g., net_rx_latency) appear in the local storage directory huatuo-local/, kernel events have been successfully captured. Query data from OpenSearch with:
curl -k -u admin:admin \
-X GET "https://localhost:9200/huatuo_bamai/_search?pretty" \
-H "Content-Type: application/json" \
-d '{"query": {"match_all": {}}}'
Example response:
{
"_index" : "huatuo_bamai",
"_id" : "yjPG_50Bu_OF-hukxKR7",
"_score" : 1.0,
"_source" : {
"hostname" : "hostname",
"region" : "dev",
"uploaded_time" : "2026-05-07T00:11:49.753166222Z",
"time" : "2026-05-07 00:11:49.753 +0000",
"tracer_name" : "net_rx_latency",
"tracer_time" : "2026-05-07 00:11:49.753 +0000",
"tracer_type" : "auto",
"tracer_data" : {
"comm" : "<nil>",
"pid" : 0,
"where" : "RX_STAGE_NETIF",
"latency_ms" : 1776078133565,
"saddr" : "127.0.0.1",
"daddr" : "127.0.0.1",
"sport" : 37736,
"dport" : 9200,
"seq" : 1080592402,
"ack_seq" : 2465063876,
"pkt_len" : 781
}
}
}
To get the total document count without listing individual records:
curl -k -u admin:admin -X GET "https://localhost:9200/huatuo_bamai/_count?pretty"
Example response: the count value equals the total number of written records.
{
"count" : 2680,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}
Elasticsearch V8
1. Deploy Elasticsearch
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.15.5
docker run -d --name elasticsearch --network host \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms1g -Xmx1g" \
-e "ELASTIC_PASSWORD=123456" \
docker.elastic.co/elasticsearch/elasticsearch:8.15.5
2. Verify Service Status
curl -k -u elastic:123456 https://localhost:9200
Example response:
{
"name" : "ab0b562f8dbd",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "aVfOVgJTQXuhZ3HGotK3ww",
"version" : {
"number" : "8.15.5",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "b10896bcfe167cce44a84ba2771d101fb596d40d",
"build_date" : "2024-11-21T22:06:13.985834967Z",
"build_snapshot" : false,
"lucene_version" : "9.11.1",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
3. Configure huatuo-bamai
Add the following configuration to huatuo-bamai.conf. The default username for the Elasticsearch container image is elastic; the password is set via the ELASTIC_PASSWORD environment variable. For a full description of storage configuration options, refer to the Configuration Guide.
[Storage.ES]
Address = "https://127.0.0.1:9200"
Index = "huatuo_bamai"
Username = "elastic"
Password = "123456"
4. Start huatuo-bamai
Use --config-dir to specify the directory containing the configuration file:
./_output/bin/huatuo-bamai --region dev --config-dir .
When files (e.g., net_rx_latency) appear in the local storage directory huatuo-local/, kernel events have been successfully captured. Query data from Elasticsearch with:
curl -k -u elastic:123456 \
-X GET "https://localhost:9200/huatuo_bamai/_search?pretty" \
-H "Content-Type: application/json" \
-d '{"query": {"match_all": {}}}'
Example response:
{
"_index" : "huatuo_bamai",
"_id" : "WtNZAJ4BQ8x-thPHEY1i",
"_score" : 1.0,
"_source" : {
"hostname" : "hostname",
"region" : "dev",
"uploaded_time" : "2026-05-07T02:51:37.696263325Z",
"time" : "2026-05-07 02:51:37.696 +0000",
"tracer_name" : "net_rx_latency",
"tracer_time" : "2026-05-07 02:51:37.696 +0000",
"tracer_type" : "auto",
"tracer_data" : {
"comm" : "<nil>",
"pid" : 0,
"where" : "RX_STAGE_NETIF",
"latency_ms" : 1776078133565,
"saddr" : "127.0.0.1",
"daddr" : "127.0.0.1",
"sport" : 2379,
"dport" : 36706,
"seq" : 950542706,
"ack_seq" : 1960972383,
"pkt_len" : 91
}
}
}
To get the total document count without listing individual records:
curl -k -u elastic:123456 -X GET "https://localhost:9200/huatuo_bamai/_count?pretty"
Example response: the count value equals the total number of written records.
{
"count" : 2680,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}
Elasticsearch V7
Elasticsearch V7 uses HTTP by default. Replace https with http in all commands.
1. Deploy Elasticsearch
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.10.1
docker run -d --name elasticsearch --network host \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms1g -Xmx1g" \
-e "ELASTIC_PASSWORD=123456" \
docker.elastic.co/elasticsearch/elasticsearch:7.10.1
2. Verify Service Status
curl -k -u elastic:123456 http://localhost:9200
Example response:
{
"name" : "d88c9e8df48b",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "_ZZefWx4SniAc255t_lIVg",
"version" : {
"number" : "7.10.1",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "1c34507e66d7db1211f66f3513706fdf548736aa",
"build_date" : "2020-12-05T01:00:33.671820Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
3. Configure huatuo-bamai
[Storage.ES]
Address = "http://127.0.0.1:9200"
Index = "huatuo_bamai"
Username = "elastic"
Password = "123456"
4. Start huatuo-bamai
Use --config-dir to specify the directory containing the configuration file:
./_output/bin/huatuo-bamai --region dev --config-dir .
When files (e.g., net_rx_latency) appear in the local storage directory huatuo-local/, kernel events have been successfully captured. Query data from Elasticsearch with:
curl -k -u elastic:123456 \
-X GET "http://localhost:9200/huatuo_bamai/_search?pretty" \
-H "Content-Type: application/json" \
-d '{"query": {"match_all": {}}}'
To get the total document count:
curl -k -u elastic:123456 -X GET "http://localhost:9200/huatuo_bamai/_count?pretty"
⚙️ How It Works
System Architecture
The HUATUO Storage module runs on each node. It writes kernel events captured by the Tracer to the local directory and to Elasticsearch or OpenSearch. Both backends share the same [Storage.ES] configuration interface and are differentiated by address.
The remote write path uses the ES/OpenSearch Bulk API (_bulk): events are queued in an in-memory buffer and submitted in batches by background workers based on size and time thresholds, with transport-layer retries on transient failures.
graph TB
subgraph kernel["Linux Kernel"]
K1[Kernel Events]
K2[AutoTracing]
end
subgraph huatuo["HUATUO Agent (node-level)"]
T["Tracer Layer"]
L["Local Directory\nhuatuo-local/"]
S["Storage Module\nBulkIndexer Buffer"]
end
subgraph backends["Storage Backends"]
ES[Elasticsearch]
OS[OpenSearch]
end
kernel --> T
T --> L
T --> S
S -->|Bulk API + auto retry| ES
S -->|Bulk API + auto retry| OS
Write Flow
Save returns immediately after the event is buffered. Background workers flush the buffer to the remote backend when any of the following triggers fire: byte threshold, time threshold, or process shutdown. The local directory write is synchronous and independent of the remote Bulk path.
sequenceDiagram
participant T as Tracer Layer
participant L as Local Directory (huatuo-local/)
participant S as Storage Module (BulkIndexer)
participant B as ES / OpenSearch
T->>S: Kernel event captured, serialized to JSON
par Local path (sync)
S->>L: Write to local file
and Remote path (async batch)
S->>S: Enqueue into bulk buffer, return immediately
Note over S: Flush on 5 MB / 1 s / shutdown
S->>B: POST /_bulk (multiple records)
B-->>S: 200 OK + per-item results
Note over S: Failed items reported via OnFailure callback
end
Bulk Write Mechanism
Buffering and Flush Triggers
| Parameter | Value | Meaning |
|---|---|---|
FlushBytes |
5 MB | Flush when accumulated bytes reach the threshold |
FlushInterval |
1 s | Force-flush 1 second after the previous flush |
NumWorkers |
4 | Concurrent workers submitting Bulk requests |
| Process shutdown | Close(ctx) |
SIGTERM/SIGINT triggers a 10 s bounded drain |
Two-Tier Retry Policy
Bulk failures are split into two layers with different retry semantics:
| Layer | Trigger | Behavior | Retried? |
|---|---|---|---|
| Whole-batch retry | Transport error (connect / timeout / TLS) HTTP status: 429 / 502 / 503 / 504 |
Client retries with exponential backoff: 100 ms → 200 ms → 400 ms → 800 ms, up to 3 attempts | ✅ auto |
| Whole-batch reject | HTTP status: 400 / 401 / 403 / 404 / 413, etc. |
Not retried; all records in the batch are dropped, an error is logged via OnError |
❌ drop |
| Per-item failure | 200 OK with per-item error: version conflict, mapping error, document too large | Not retried; only the failed item is dropped, OnFailure logs index/id/status/type/reason |
❌ drop |
| Per-item success | 200 OK with per-item success | Considered durably indexed | — |
Why this design: 429/5xx and transport errors signal transient remote unavailability where retries are effective; 4xx (except 429) and per-item errors are client-side semantic issues (data shape, permissions) where retries would only amplify the failure — they should be surfaced via logs for human investigation.
Data-Loss Scenarios
In all three scenarios below, Save returns nil but the event never reaches the index:
- Abnormal process exit:
SIGKILLor host power loss drops whatever is still buffered in the BulkIndexer (the local directory still keeps a copy).- Mitigation: SIGTERM/SIGINT trigger graceful shutdown;
Closeforce-flushes the buffer with a 10 s deadline.
- Mitigation: SIGTERM/SIGINT trigger graceful shutdown;
- Whole-batch permanent rejection: 4xx (non-429) errors discard every record in the batch. Common causes: disabled index, expired credentials, document exceeding the cluster’s
http.max_content_length.- Diagnosis:
OnErrorlog includes ES’stypeandreason.
- Diagnosis:
- Permanent per-item failure: mapping conflict, version conflict, malformed document.
- Diagnosis:
OnFailurelog identifies the record byindex/id.
- Diagnosis:
The local directory is always a fallback: even if remote writes are lost, events remain available in
huatuo-local/as the eventual-consistency safety net.
Problems This Solves
Replacing per-event Index API calls with a buffered BulkIndexer + auto-retry addresses four classes of problems:
| Problem | Old approach bottleneck | Bulk approach improvement |
|---|---|---|
| TLS handshake CPU cost | One HTTPS handshake per event saturated CPU under FIPS/RSA-PSS | Many events share one connection and one handshake; TLS PSK tickets cached |
| Remote RTT throughput ceiling | One round-trip per event capped node-level write rate | One Bulk request carries up to 5 MB; throughput scales with batch size |
| Transient remote jitter / 429 throttle | A single failure dropped the event with no retry | Client-level retry absorbs short-lived faults |
| Decoupling tracer layer from backend | Slow remote backed pressure into capture, delaying tracing | Async buffer decouples capture from network — capture is no longer blocked on remote latency |
🌟 Stay Connected
6.2 - Data Source Configuration
HUATUO supports integrating with Prometheus for metrics collection and Elasticsearch for log storage. This document describes how to configure data sources and import dashboards in Grafana.
Metrics Collection
1. Port Forwarding for Testing
$ kubectl port-forward -n default --address=0.0.0.0 pod/huatuo-XXXX 19704:19704
2. Verify Metrics Endpoint
Access the metrics endpoint to verify it’s working:
http://172.16.20.113:19704/metrics
If metrics are displayed, the service is running correctly.
3. Configure Prometheus Scraping
There are two approaches to configure Prometheus for scraping HUATUO metrics:
Option 1: Using Annotations
Add annotations to the Pod template metadata:
template:
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "19704"
prometheus.io/path: "/metrics"
Option 2: Using ServiceMonitor
Create huatuo-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: huatuo
labels:
app: huatuo
spec:
clusterIP: None
ports:
- name: metrics
port: 19704
targetPort: 19704
protocol: TCP
selector:
app: huatuo
Create huatuo-servicemonitor.yaml:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: huatuo
namespace: default
labels:
release: prometheus
spec:
namespaceSelector:
matchNames:
- default
selector:
matchLabels:
app: huatuo
endpoints:
- port: metrics
path: /metrics
interval: 30s
scrapeTimeout: 10s
4. Query Metrics in Prometheus
Use the following pattern to query HUATUO metrics:
huatuo_*
If results are returned, metrics collection is working properly.
Log Collection
Query logs from Elasticsearch:
$ curl -u elastic:123456 "http://172.16.15.118:9200/huatuo_bamai/_search?pretty"
Grafana Data Source Configuration
1. Configure Prometheus Data Source
Refer to build/docker/datasource/ for detailed configuration files.
2. Configure Elasticsearch Data Source
In Grafana, add a new Elasticsearch data source with the following settings:
- URL:
http://172.16.15.118:9200 - Authentication: Basic Authentication
- Username:
elastic - Password:
123456 - Index name:
huatuo_bamai - Time field name:
uploaded_time
Dashboard Import
1. Export Dashboard from Console
- Access
http://console.huatuo.tech/dashboards(Username:huatuo, Password:huatuo1024) - Select the desired dashboard
- Click Export -> Export as JSON
- Check “Export the dashboard to use in another instance”
- Click Copy to clipboard
2. Import Dashboard to Local Grafana
- In your local Grafana, navigate to Dashboards -> Import
- Paste the copied JSON content
- Click Load
- Configure data sources and click Import
Troubleshooting
Issue: “datasource not found” error when importing the “HuaTuo Root Cause Analysis AutoTracing” dashboard.
Solution:
- Manually replace the datasource UID in the dashboard JSON
- Find your Elasticsearch datasource UID from the URL (e.g.,
dflcs0w2ghybkafromhttp://172.16.15.118:3000/connections/datasources/edit/dflcs0w2ghybka) - Replace all occurrences of
"uid": "${DS_HUATUO-BAMAI-ES}"with your actual datasource UID - Re-import the dashboard
6.3 - Events Watch
📖 Overview
/v1/events/watch is HUATUO’s real-time kernel event subscription endpoint. A single HTTP POST long-lived connection streams kernel anomaly events from the node continuously. Events are wrapped in the CloudEvents 1.0 specification and delivered via the Server-Sent Events (SSE) protocol.
🎯 Use Cases
Kernel event subscription surfaces OS-level anomaly signals directly to higher-level systems, eliminating the latency and overhead of traditional polling. The following are typical integration scenarios.
Fault Self-Healing
Kernel events are the primary signal source for self-healing decisions. After subscribing to events/watch, a healing controller can trigger remediation the moment an event occurs, without waiting for an alert to propagate through a monitoring pipeline:
- OOM self-healing: On receiving an
oomevent, immediately scale, restart, or drain traffic from the triggering container. Reduces service interruption from minutes to seconds. - Hung task self-healing: On receiving a
hungtaskevent, automatically cordon the node and evict Pods to prevent cascading blockage from spreading across the cluster. - Network fault self-healing: On receiving a
netdev_txqueue_timeoutornetdev_bonding_lacpevent, trigger a NIC reset or traffic failover to restore the network link within minutes. - I/O storm self-healing: On receiving an
iotracingevent, dynamically throttle the affected container’s disk I/O quota via cgroup blkio to protect co-located services on the same node.
Observability Platforms
Integrating HUATUO kernel events into an observability platform adds a kernel-level perspective beyond application metrics and logs:
- Event timeline correlation: Overlay
softlockup,oom, and other kernel events onto Grafana timelines, aligning them precisely with application error rates and latency curves for root-cause analysis. - Anomaly-driven alerting: Replace fixed-threshold alerts with kernel events to reduce false positives. For example, a
rashardware error event triggers a high-priority alert directly, without relying on a CPU error rate crossing a threshold. - Capacity and stability analysis: Subscribe to
memburst,dload, and other AutoTracing events over time to establish a node stability baseline and provide kernel-level data for capacity planning. - Multi-dimensional drill-down: Events carry container ID, namespace, region, and other context fields. Alert links can drill down directly to the corresponding Pod, Node, or Region view.
Security Auditing and Compliance
- Anomalous behavior detection: A cluster of
oom,hungtask, orsoftlockupevents outside business peak hours may indicate resource abuse or a malicious workload, triggering a security review workflow. - Event retention and traceability: Write the CloudEvents stream to a message queue (Kafka, Pulsar) or object storage to satisfy the event retention requirements of security compliance frameworks.
Chaos Engineering and Load Testing
- Fault injection verification: After injecting network latency or memory pressure via a chaos engineering platform, subscribe to
net_rx_latencyandmemburstevents in real time to verify the fault is active, replacing manual observation. - Load test baseline: Subscribe to all events during a load test. The timestamp of the first kernel anomaly event precisely marks the system’s stress threshold.
AIOps
- Event-driven root-cause analysis: Feed kernel events as features into AI/ML models alongside application metrics for multi-dimensional root-cause inference, reducing manual investigation time.
- Predictive maintenance: Model
rashardware errors andnetdev_bonding_lacphardware-layer events to detect anomalies before a device fails completely, triggering proactive migration. - Intelligent suppression and aggregation: Automatically aggregate similar events within the same time window to avoid alert storms. Deliver a concise root-cause summary to on-call engineers.
💎 Value
| Dimension | Traditional Approach | With HUATUO events/watch |
|---|---|---|
| Timeliness | Alert trigger latency: 1–5 minutes | Real-time kernel event push; latency < 1 s |
| Signal accuracy | Metric threshold-based; high false-positive rate | Events originate from kernel decisions; false-positive rate near zero |
| Context richness | Limited metric dimensions | Full context: container, node, region, and more |
| Integration cost | Requires custom eBPF collection or a third-party agent | Single HTTP POST to subscribe; standard CloudEvents format |
| Protocol compatibility | Vendor-specific formats | Follows CloudEvents 1.0; compatible with any conformant platform |
🚀 Usage
1. CloudEvents Specification
1.1 CloudEvents 1.0 Envelope Fields
Each pushed event is a JSON object conforming to the CloudEvents 1.0 specification:
| Field | Type | Description |
|---|---|---|
specversion |
string | Fixed value "1.0" |
id |
string | Unique event identifier (UUID v4), generated independently per event |
source |
string | Event source path, format: /huatuo/{hostname}/{tracer_name} |
type |
string | Fixed value "tech.huatuo.kernel.event" |
datacontenttype |
string | Fixed value "application/json" |
time |
string | Event collection timestamp (RFC 3339, nanosecond precision, UTC) |
data |
object | Event payload — the WatchEventData struct |
1.2 HUATUO Event Payload (WatchEventData)
The data field contains the standard HUATUO event record:
{
"specversion": "1.0",
"id": "f47ac10b-58cc-4372-a567-0e02b2c3d479",
"source": "/huatuo/node-1/oom",
"type": "tech.huatuo.kernel.event",
"datacontenttype": "application/json",
"time": "2026-05-18T10:23:45.123456789Z",
"data": {
"hostname": "node-1",
"region": "cn-beijing",
"observed_timestamp": "2026-05-18T10:23:45Z",
"tracer_name": "oom",
"tracer_id": "abc123",
"tracer_run_type": "auto",
"container_id": "d3f1a2b4c5e6",
"container_hostname": "app-pod",
"container_host_namespace": "prod",
"container_type": "docker",
"container_qos": "Guaranteed"
}
}
WatchEventData field reference:
| Field | Type | Description |
|---|---|---|
hostname |
string | Node hostname |
region |
string | Region where the node is located |
observed_timestamp |
string | Kernel event timestamp (Tracer collection time) |
tracer_name |
string | Name of the tracer that triggered the event (see the event list below) |
tracer_id |
string | Unique ID of this event instance |
tracer_run_type |
string | Collection mode: auto (triggered automatically) or manual |
container_id |
string | Container ID (present for container-level events) |
container_hostname |
string | Container hostname |
container_host_namespace |
string | Namespace of the container |
container_type |
string | Container runtime type (docker, containerd, etc.) |
container_qos |
string | Container QoS class |
2. Supported Kernel Events
tracer_name |
Description |
|---|---|
oom |
Out-of-memory (OOM Killer) triggered event |
hungtask |
Kernel task stuck in D state (Hung Task) detection |
softlockup |
CPU soft lockup detection |
ras |
Hardware reliability (RAS) errors, such as ECC memory errors |
dropwatch |
Kernel network packet drop (Drop Watch) events |
netdev_events |
Network device state change events (Link Up/Down, etc.) |
netdev_txqueue_timeout |
Network device transmit queue timeout events |
netdev_bonding_lacp |
Bond device LACP protocol anomaly events |
net_rx_latency |
Network receive latency anomaly events |
softirq_tracing |
Soft IRQ excessive latency tracing events |
memory_reclaim_events |
Memory reclaim anomaly events |
cpuidle |
CPU idle rate anomaly (AutoTracing, auto-triggered) |
cpusys |
CPU system-mode usage anomaly (AutoTracing, auto-triggered) |
dload |
System load anomaly (AutoTracing, auto-triggered) |
iotracing |
I/O latency anomaly (AutoTracing, auto-triggered) |
memburst |
Memory usage spike anomaly (AutoTracing, auto-triggered) |
3. POST Request Reference
3.1 Endpoint
POST /v1/events/watch
3.2 Request Headers
Content-Type: application/json
3.3 Request Body
{
"filters": {
"tracer_name": "<regex>",
"hostname": "<regex>",
"container_hostname": "<regex>",
"container_host_namespace": "<regex>",
"region": "<regex>"
}
}
filters field reference:
| Field | Type | Required | Description |
|---|---|---|---|
tracer_name |
string | No | Filter by tracer name; supports regular expressions |
hostname |
string | No | Filter by node hostname; supports regular expressions |
container_hostname |
string | No | Filter by container hostname; supports regular expressions |
container_host_namespace |
string | No | Filter by container namespace; supports regular expressions |
region |
string | No | Filter by region; supports regular expressions |
- All filter fields are optional. Omitting or leaving a field empty matches all values.
- When multiple fields are specified, all conditions must be satisfied simultaneously (AND semantics).
- Filters are evaluated server-side; only matching events are pushed to the client.
3.4 Response Format (SSE Stream)
After the connection is established, the server continuously pushes events in SSE format:
data: {"specversion":"1.0","id":"...","source":"/huatuo/node-1/oom",...}\n\n
The server also sends periodic heartbeat comment lines to keep the connection alive:
: ping\n
4. EventsWatch Configuration
Configure the [EventsWatch] section in the HUATUO configuration file (huatuo-bamai.conf):
[EventsWatch]
# Maximum number of concurrent client connections. New connections receive HTTP 429 when the limit is reached.
# Default: 100
MaxClients = 100
# SSE heartbeat interval in seconds. Prevents proxies and load balancers from closing idle connections.
# The connection is closed after three consecutive heartbeat write failures.
# Default: 30
KeepAliveInterval = 30
| Field | Default | Description |
|---|---|---|
MaxClients |
100 | Maximum concurrent /v1/events/watch connections. Excess connections receive HTTP 429. |
KeepAliveInterval |
30 | Heartbeat interval in seconds. Should not exceed the upstream proxy’s idle timeout. Recommended range: 15–60 s. |
5. curl Examples
5.1 Subscribe to All Kernel Events
curl -s -N -X POST http://<node-ip>:19704/v1/events/watch \
-H "Content-Type: application/json" \
-H "Accept: text/event-stream" \
-H "Cache-Control: no-cache" \
-H "Connection: keep-alive" \
-d '{}'
5.2 Subscribe to OOM Events Only
curl -s -N -X POST http://<node-ip>:19704/v1/events/watch \
-H "Content-Type: application/json" \
-H "Accept: text/event-stream" \
-H "Cache-Control: no-cache" \
-H "Connection: keep-alive" \
-d '{"filters": {"tracer_name": "^oom$"}}'
5.3 Subscribe to Network Events on a Specific Node
curl -s -N -X POST http://<node-ip>:19704/v1/events/watch \
-H "Content-Type: application/json" \
-H "Accept: text/event-stream" \
-H "Cache-Control: no-cache" \
-H "Connection: keep-alive" \
-d '{
"filters": {
"hostname": "^node-1$",
"tracer_name": "netdev|dropwatch|net_rx_latency"
}
}'
5.4 Subscribe to Container Events in the prod Namespace
curl -s -N -X POST http://<node-ip>:19704/v1/events/watch \
-H "Content-Type: application/json" \
-H "Accept: text/event-stream" \
-H "Cache-Control: no-cache" \
-H "Connection: keep-alive" \
-d '{
"filters": {
"container_host_namespace": "^prod$"
}
}'
Note: The
-Nflag disables curl buffering, causing SSE events to be printed to the terminal immediately.
6. Go Client Example
The following example shows how to subscribe to the events/watch endpoint in a Go program and consume CloudEvents in real time.
package main
import (
"bufio"
"bytes"
"context"
"encoding/json"
"fmt"
"log/slog"
"net/http"
"os"
"strings"
"time"
)
// WatchRequest is the request body sent to /v1/events/watch.
type WatchRequest struct {
Filters WatchFilters `json:"filters"`
}
type WatchFilters struct {
TracerName string `json:"tracer_name,omitempty"`
Hostname string `json:"hostname,omitempty"`
ContainerHostname string `json:"container_hostname,omitempty"`
ContainerHostNamespace string `json:"container_host_namespace,omitempty"`
Region string `json:"region,omitempty"`
}
// WatchEvent is the CloudEvents 1.0 envelope pushed by HUATUO.
type WatchEvent struct {
SpecVersion string `json:"specversion"`
ID string `json:"id"`
Source string `json:"source"`
Type string `json:"type"`
DataContentType string `json:"datacontenttype"`
Time string `json:"time"`
Data json.RawMessage `json:"data"`
}
func watchEvents(ctx context.Context, endpoint string, filters WatchFilters) error {
reqBody, err := json.Marshal(WatchRequest{Filters: filters})
if err != nil {
return fmt.Errorf("marshal request: %w", err)
}
req, err := http.NewRequestWithContext(ctx, http.MethodPost, endpoint, bytes.NewReader(reqBody))
if err != nil {
return fmt.Errorf("create request: %w", err)
}
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Accept", "text/event-stream")
client := &http.Client{Timeout: 0} // no timeout for SSE long-lived connections
resp, err := client.Do(req)
if err != nil {
return fmt.Errorf("connect: %w", err)
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return fmt.Errorf("unexpected status: %d", resp.StatusCode)
}
scanner := bufio.NewScanner(resp.Body)
for scanner.Scan() {
line := scanner.Text()
// skip heartbeat comment lines and blank lines
if line == "" || strings.HasPrefix(line, ":") {
continue
}
// SSE data line format: `data: <json>`
data, ok := strings.CutPrefix(line, "data: ")
if !ok {
continue
}
var event WatchEvent
if err := json.Unmarshal([]byte(data), &event); err != nil {
slog.Warn("parse event", "err", err)
continue
}
fmt.Printf("[%s] source=%s id=%s\n", event.Time, event.Source, event.ID)
fmt.Printf(" data: %s\n", event.Data)
}
return scanner.Err()
}
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Minute)
defer cancel()
err := watchEvents(ctx, "http://192.168.1.10:19704/v1/events/watch", WatchFilters{
TracerName: "oom|hungtask|softlockup",
})
if err != nil {
slog.Error("watch events", "err", err)
os.Exit(1)
}
}
6.1 Using the Official pkg/types Package (Recommended)
If your project shares the same Go module as HUATUO, use the official types directly:
import pkgtypes "huatuo-bamai/pkg/types"
var event pkgtypes.WatchEvent
if err := json.Unmarshal([]byte(data), &event); err != nil { ... }
// WatchEvent.Data is json.RawMessage (deferred parsing); a second unmarshal is required to access typed fields
dataBytes, err := json.Marshal(event.Data)
if err != nil {
slog.Warn("marshal event data", "err", err)
return
}
var payload pkgtypes.WatchEventData
if err := json.Unmarshal(dataBytes, &payload); err != nil {
slog.Warn("unmarshal event data", "err", err)
return
}
fmt.Println("tracer:", payload.TracerName)
fmt.Println("observed_timestamp:", payload.ObservedTimestamp)
6.2 Reconnection
In production, network interruptions or service restarts will drop the connection. Use exponential backoff to reconnect:
func watchWithRetry(ctx context.Context, endpoint string, filters WatchFilters) {
backoff := time.Second
for {
if err := watchEvents(ctx, endpoint, filters); err != nil {
if ctx.Err() != nil {
return
}
slog.Warn("disconnected, retrying", "err", err, "backoff", backoff)
// time.NewTimer + Stop releases the timer immediately when the context is cancelled
timer := time.NewTimer(backoff)
select {
case <-ctx.Done():
timer.Stop()
return
case <-timer.C:
}
if backoff < 30*time.Second {
backoff *= 2
}
}
}
}
⚙️ How It Works
Architecture
HUATUO Agent runs on each node. It hooks into critical kernel paths via eBPF, Kprobe, and Tracepoint, collects kernel anomaly events, applies filters, wraps them as CloudEvents, and pushes them to multiple concurrent SSE subscribers.
graph TB
subgraph kernel["Linux Kernel"]
K1[OOM Killer]
K2[Hung Task Detection]
K3[Soft Lockup Detection]
K4[RAS Hardware Errors]
K5[Network Subsystem]
K6[AutoTracing]
end
subgraph huatuo["HUATUO Agent (per node)"]
T["Tracer Collection Layer\neBPF / Kprobe / Tracepoint"]
F["Filter\nhostname / tracer / namespace / region"]
CE["CloudEvents 1.0 Wrapper\nid / source / time / data"]
EW["EventsWatch Dispatcher\nSSE connection management"]
end
subgraph clients["Subscribers"]
C1[Fault Self-Healing System]
C2[Observability Platform]
C3[AIOps System]
C4[Security Audit System]
end
kernel --> T
T --> F
F --> CE
CE --> EW
EW -->|SSE push| C1
EW -->|SSE push| C2
EW -->|SSE push| C3
EW -->|SSE push| C4
Event Collection and Push
After the client issues a POST request, the connection stays open. Each time the kernel triggers an anomaly event, HUATUO Agent filters and wraps it, then writes it immediately to all matching SSE streams. No client polling is required.
sequenceDiagram
participant C as Client
participant EW as EventsWatch
participant T as Tracer Layer
participant K as Linux Kernel
C->>EW: POST /v1/events/watch {"filters": {...}}
EW-->>C: 200 OK (Content-Type: text/event-stream)
loop SSE long-lived connection
K->>T: Kernel event triggered (oom / hungtask / softlockup ...)
T->>EW: Report raw event
EW->>EW: Apply filter
alt Filter matched
EW-->>C: data: {CloudEvents JSON}\n\n
else No match
note over EW: Discard, do not push
end
EW-->>C: : ping (keepalive, every KeepAliveInterval seconds)
end
Event Processing Pipeline
From kernel event generation to client delivery, three stages are involved: collection, filtering, and wrapping. End-to-end latency is under 1 second.
flowchart LR
A([Kernel anomaly triggered]) --> B["Tracer collection\neBPF / Kprobe"]
B --> C{Filter matched?}
C -- No --> D([Discard])
C -- Yes --> E["Wrap as CloudEvents 1.0\nid / source / time / data"]
E --> F[Write to SSE stream]
F --> G([Push to subscribers])
🌟 Stay Connected
6.4 - Profiling
Flame Graph Formats
In profiling, collapsed and flamegraph are the two most common formats, corresponding to the “raw data” and “visual view” layers respectively.
Collapsed Format
Standard Syntax and Format
The collapsed format (also called folded stacks) was defined by Brendan Gregg and serves as the raw text input format for flame graphs. Each line represents a unique call stack and its sample count.
Basic rule:
frame1;frame2;frame3;...;frameN COUNT
| Component | Description |
|---|---|
frame1 |
Stack bottom (entry/root frame), e.g. main, start_thread |
; |
Frame separator (semicolon) |
frameN |
Stack top (currently executing frame, i.e. the sampled point) |
COUNT |
Sample count (integer), separated from the stack frames by a space |
Format details:
- One unique call stack per line; samples with the same stack path have their counts merged
- Frame order: left to right is root → leaf (call chain direction)
- Blank lines and lines starting with
#are treated as comments and ignored during parsing - The semantics of COUNT depend on the analysis mode: for CPU sampling it is the number of samples, for memory allocation it is the number of bytes allocated, for lock analysis it is the contention time in milliseconds
Extended specification:
Some profiling tools (e.g. async-profiler) add frame type annotations on top of the standard format to identify the runtime category of a frame:
frameName_{type} COUNT
| Annotation | Meaning | Description |
|---|---|---|
_[j] |
JIT compiled Java | Java method after JIT compilation |
_[i] |
Interpreted Java | Java method executed by the interpreter |
_[k] |
Kernel | Kernel-mode frame |
_[n] |
Native C/C++ | Native C/C++ frame |
_[t] |
Thread | Thread frame |
Additionally, some tools support a weighted collapsed format for differential flame graphs:
frame1;frame2;frameN WEIGHT
Where WEIGHT is a floating-point number representing the weight of the stack rather than a simple count.
Sample Examples
CPU profiling example (data from the async-profiler official documentation):
FileConverter.main;FileConverter.convertFile;FileConverter.saveResult 21
FileConverter.main;FileConverter.convertFile;FileConverter.saveResult;java/io/DataOutputStream.writeInt 1
FileConverter.main;FileConverter.convertFile;FileConverter.saveResult;java/io/DataOutputStream.writeInt;java/io/ByteArrayOutputStream.write 5
FileConverter.main;FileConverter.convertFile;FileConverter.saveResult;java/io/DataOutputStream.writeUTF;java/io/DataOutputStream.writeUTF 12
FileConverter.main;FileConverter.convertFile;FileConverter.saveResult;java/io/DataOutputStream.writeUTF;java/io/DataOutputStream.writeUTF;java/lang/String.length 3
FileConverter.main;FileConverter.convertFile;FileConverter.saveResult;java/io/DataOutputStream.writeUTF;java/io/DataOutputStream.writeUTF;java/io/DataOutputStream.write 6
start_thread;thread_native_entry;Thread::call_run;VMThread::run;VMThread::inner_execute;VMThread::evaluate_operation;VM_Operation::evaluate;VM_GenCollectForAllocation::doit;GenCollectedHeap::satisfy_failed_allocation;GenCollectedHeap::do_collection;GenCollectedHeap::collect_generation;DefNewGeneration::collect;DefNewGeneration::FastEvacuateFollowersClosure::do_void 12
Example with frame type annotations (async-profiler extension):
Main.run_[j];Service.process_[j];DAO.query_[j];mysql_real_query_[n] 45
Main.run_[j];Service.process_[j];DAO.query_[j];recv_[k] 18
Core Use Cases
| Use Case | Description |
|---|---|
| Flame graph generation | Standard input format for visualization tools like flamegraph.pl and inferno |
| Differential analysis | Compare two collapsed files to produce a red-blue differential flame graph for detecting performance regressions |
| Programmatic processing | Plain text format suitable for custom aggregation and filtering with awk, sed, Python, etc. |
| Cross-tool interoperability | Universal standard defined by Brendan Gregg; supported by virtually all flame graph toolchains |
| Long-term storage | Compact text format suitable for archiving and version comparison |
| CI/CD integration | Enables automated collection, diffing, and threshold-based regression detection in pipelines |
Generation command example:
# Using async-profiler as an example
asprof -d 30 -f profile.collapsed -o collapsed <PID>
Flamegraph Format
Standard Syntax and Format
The flamegraph format is a self-contained HTML file with embedded SVG visualization and JavaScript interaction logic, which can be opened directly in a browser.
Structural composition:
flamegraph.html
├── HTML skeleton + CSS styles
├── SVG flame graph body
│ ├── <g> rectangle block for each frame
│ │ ├── <title> frame name + sample count/percentage
│ │ └── <rect> position, width, height, color
│ └── ...
├── JavaScript interaction logic
│ ├── Click to zoom (zoom into subtree)
│ ├── Search & highlight
│ ├── Tooltip on hover
│ └── Reset zoom
└── Metadata (title, total samples, etc.)
Visual encoding rules:
| Dimension | Encoding Meaning |
|---|---|
| X axis | Call stack frames sorted alphabetically (not a timeline); width proportional to sample count |
| Y axis | Call stack depth; bottom is the root frame, top is the leaf frame |
| Frame width | Proportion of samples where this frame appears in the stack; wider frames consume more resources |
| Frame color | Identifies the frame type (see table below) |
Frame color specification (based on async-profiler):
Note: Flame graph color schemes are not a cross-tool standard. The original
flamegraph.plby Brendan Gregg uses random warm tones with no semantic meaning;perf/bpftracetypically colors by DSO or uses random colors; async-profiler colors by frame type semantics. The following is the async-profiler color specification:
| Color | Frame Type | Description |
|---|---|---|
| 🟢 Green | Java (interpreted) | Java method executed by the interpreter |
| 🟡 Yellow/Orange | Java (JIT compiled) | Java method after JIT compilation |
| 🔴 Red | C/C++ (native) | Native C/C++ code |
| 🔵 Blue | Kernel | Kernel-mode code |
| ⬜ Gray | Other/Unknown | Other types or unknown frames |
Extended features (based on async-profiler):
- Icicle Graph: Displays the call chain top-down (root at the top), which better suits top-down reading habits. Toggle via the
--reverseoption or the Reverse button in the browser - Multi-thread view: Call stacks from different threads are displayed side by side at the root level
- Search highlighting: Matching frames are highlighted in purple; non-matching frames are dimmed
- Sample info tooltip: Hover to display frame name, sample count, and percentage of total samples
- Cutoff frames: Frames marked as
[...]indicate stack truncation (e.g. due to stack depth limits)
Sample Examples
Generation command example:
# Using async-profiler as an example
asprof -d 30 -f flamegraph.html <PID>
Interactive operations:
- Click a frame: Zoom to make the frame full-width, showing only its subtree
- Search box: Enter a keyword; matching frames are highlighted
- Hover: Display frame name, sample count, and percentage
- Reset Zoom: Restore the global view
Core Use Cases
| Use Case | Description |
|---|---|
| Hotspot identification | Visually identify the widest frame blocks to quickly find the code paths consuming the most CPU/memory |
| Root cause analysis | Trace upward from leaf frames to understand the call chain context of resource consumption |
| Team collaboration | HTML files can be shared directly; viewable in a browser with no additional tools required |
| Optimization verification | Generate flame graphs before and after optimization; compare frame width changes to verify effectiveness |
| Non-specialist friendly | Visual form is easier to understand for non-performance engineers, facilitating cross-team communication |
Format Comparison
| Dimension | Collapsed | Flamegraph |
|---|---|---|
| Format type | Plain text | HTML + SVG |
| Human readability | Medium (requires understanding stack frame syntax) | High (visual, intuitive) |
| Machine readability | High (easy to parse, easy to diff) | Low (requires parsing HTML/SVG) |
| Interactivity | None | Supports zoom, search, tooltip |
| File size | Very small (KB scale) | Larger (hundreds of KB to MB scale) |
| Toolchain dependency | None (plain text) | Browser |
| Differential analysis | Natively supported (diff two files) | Requires conversion to collapsed first |
| Typical use case | Programmatic processing, CI comparison, archiving | Manual analysis, team sharing, presentation |
Typical workflow:
Collect ──► collapsed ──► flamegraph.html (manual analysis)
│
├──► Differential flame graph (regression detection)
├──► Custom aggregation scripts
└──► Archive storage
6.5 - Network Drop Monitoring (dropwatch)
Overview
dropwatch is a kernel network drop observability tool provided by HUATUO. It attaches to the kernel tracepoint tracepoint/skb/kfree_skb to capture network drop events in real time, and outputs the full drop context: protocol type, IP five-tuple, process name, PID, network device, MAC address, and the complete kernel call stack that triggered the drop.
dropwatch supports kernel-side filtering based on tcpdump-style filter expressions. The filter logic is compiled into eBPF bytecode at load time by the built-in pure-Go pcap compiler internal/pcapfilter. Filtering is performed entirely in kernel mode — only matching packets are reported to user space, reducing performance impact on the host.
In addition, dropwatch supports device whitelist/blacklist filtering, global per-second rate limiting, and integration with huatuo-bamai to store drop events in Elasticsearch for long-term analysis.
Scenarios
1. Kubernetes Cloud-Native Network Drop Diagnosis
In scenarios such as container migration, frequent Pod restarts, and Service port conflicts, dropwatch captures kfree_skb events in real time and correlates them with specific containers to quickly identify the root cause of packet drops. Combined with --filter "tcp and port <service-port>" to filter specific business traffic, the mean time to root cause is reduced from hours to minutes.
2. Network Performance Spike Analysis
For intermittent spikes in network latency or drops in throughput, dropwatch collects drop events and, together with the kernel call stack, identifies the specific kernel function where the drop occurred (e.g. tcp_v4_rcv, ip_output). This helps distinguish whether the cause is a firewall drop, routing failure, buffer overflow, or other reasons.
3. Multi-Tenant Network Isolation Troubleshooting
In container environments that share network namespaces or veth devices, use --device to filter by network device and --filter to filter by protocol. This precisely captures drop events for the target container, preventing other tenants’ traffic from interfering with the diagnosis.
4. Observability Platform Integration
Use --output-storage to send drop events to huatuo-bamai, which stores them in Elasticsearch for multi-dimensional correlation with metrics and logs. Overlay drop events on a Grafana timeline, aligned with application error rates and latency curves, to correlate kernel drops with application anomalies precisely.
Usage
1. Filter Expressions
Filter expressions use tcpdump syntax. The built-in pure-Go pcap compiler internal/pcapfilter compiles them into eBPF bytecode at load time. Filtering is performed entirely in kernel mode, reducing host impact — only matching packets are reported to user space.
1.1 Supported Expressions
internal/pcapfilter supports a subset of the standard tcpdump syntax. The following primitives are reliable:
Protocols
ip ip6 tcp udp icmp icmp6 igmp pim esp ah vrrp arp rarp
ip proto tcp ip6 proto udp (protocol names only; numeric protocol numbers not supported)
Host addresses
host 10.0.0.1
src host 10.0.0.1
dst host 10.0.0.1
Ports
port 80
src port 443
dst port 8080
Networks (CIDR)
net 10.0.0.0/8
src net 192.168.1.0/24
dst net 172.16.0.0/12
Multicast and Ethernet addresses
ip multicast ip6 multicast multicast ether multicast
ether host 00:11:22:33:44:55
Boolean operators and grouping
tcp and port 80
tcp or udp
not arp
tcp and (port 80 or port 443)
ip and src net 192.168.1.0/24 and tcp dst port 3306
1.2 Unsupported Expressions
The following expressions are not supported. Using them causes compilation failures or incorrect match results:
| Expression | Reason |
|---|---|
tcp[tcpflags] & tcp-syn != 0, ip[8], tcp[0:4] |
Byte-offset expressions (proto[offset:size]) not implemented |
ip proto 6, ip6 proto 17 |
Numeric protocol numbers not supported; use names (e.g. ip proto tcp) |
ether proto 0x0800 |
Hex EtherType not supported; use names (e.g. ether proto ip) |
sctp |
Keyword not recognized |
portrange 80-90, tcp portrange 1-100 |
Port ranges not supported |
less N, greater N |
Packet-length filtering not supported |
ip broadcast, ether broadcast |
Broadcast matching not supported |
vlan, mpls, pppoes |
Tunnel/encapsulation keywords not supported |
gateway |
Not supported |
1.3 Examples
# Monitor all TCP drops (default — reliable in both L2 and L3 contexts)
--filter "tcp"
# TCP and UDP
--filter "tcp or udp"
# Specific destination host (applies to both TCP and UDP)
--filter "dst host 10.0.0.1"
# Specific port
--filter "tcp and port 443"
# Exclude a noisy host
--filter "tcp and not host 169.254.169.254"
# Specific subnet + specific port
--filter "src net 192.168.1.0/24 and tcp dst port 3306"
# Monitor non-TCP drops (UDP and ICMP only — avoid "not tcp", which captures unknown L3 events)
--filter "udp or icmp"
# Monitor ARP drops only (effective only in L2 context; never matches at L3)
--filter "arp"
--filter "ip"/--filter "ip6"now correctly match the corresponding IP protocol family (L2 by EtherType, L3 by version nibble). If you only care about a specific transport layer or host, prefer the more precisetcp,udp,host, orip proto <name>.
2. Running dropwatch
dropwatch [flags]
| Flag | Default | Description |
|---|---|---|
--bpf-path <path> |
required | Path to the dropwatch eBPF object file |
--filter <expr> |
(none) | tcpdump-style filter expression |
--device <names> |
(none) | Device whitelist: only collect drops from these devices; comma-separated (e.g. eth0,eth1) |
--device-excluded <names> |
(none) | Device blacklist: exclude drops from these devices; mutually exclusive with --device |
--duration <n> |
0 | Stop after N seconds (0 = run until Ctrl-C) |
--output <json|text> |
text |
Output format; ignored when --output-storage is set |
--output-storage <path> |
(none) | Send events to huatuo-bamai via Unix socket |
--task-id <id> |
(none) | Task ID for this session; typically used with --output-storage |
--max-events-per-second <n> |
0 | Global rate limit in events/sec (0 = unlimited); applied after --device / --filter |
--filter and device filtering are orthogonal; when both are specified, both apply (AND semantics). If neither --device nor --device-excluded is specified, all devices are collected. --device and --device-excluded are mutually exclusive; whitelist mode drops SKBs without a net_device, while blacklist mode passes them.
Examples
# Text output, monitor TCP drops on all devices
sudo dropwatch --bpf-path bpf/dropwatch.o --filter "tcp"
# Monitor drops on eth0 only
sudo dropwatch --bpf-path bpf/dropwatch.o --device eth0 --output json
# Exclude loopback
sudo dropwatch --bpf-path bpf/dropwatch.o --device-excluded lo --output json
# Combine device and protocol filters
sudo dropwatch --bpf-path bpf/dropwatch.o --device eth0 --filter "tcp and port 443" --output json
# Capture for 60 seconds and exit
sudo dropwatch --bpf-path bpf/dropwatch.o --filter "tcp and port 443" --duration 60 --output json
# Forward events to a running huatuo-bamai instance
sudo dropwatch --bpf-path bpf/dropwatch.o --filter "tcp" --output-storage /var/run/huatuo/events.sock
# Use jq to filter and show only RST packets
sudo dropwatch --bpf-path bpf/dropwatch.o --output json 2>/dev/null | jq 'select(.layers.tcp.flags == "RST")'
# Capture 10 seconds of JSON output, excluding events whose stack contains ip_finish_output
sudo dropwatch --output json --duration 10 --bpf-path bpf/dropwatch.o | jq -c 'select(.stack | test("ip_finish_output") | not)'
# Capture 10 seconds of JSON output, printing all fields except stack
sudo dropwatch --output json --duration 10 --bpf-path bpf/dropwatch.o | jq -c 'del(.stack)'
jq -c compresses each matching event into a single-line JSON, convenient for saving as NDJSON or further pipe processing. test("ip_finish_output") checks whether stack matches the regex; not negates the result, so the command above excludes stacks containing ip_finish_output. Remove | not to keep only those containing ip_finish_output. del(.stack) removes the stack field from the jq output, useful for viewing just the timestamp, device, process, packet_* metadata, and layers protocol fields. For kernel-side call-stack filtering, configure EventTracing.IssuesList in huatuo-bamai (see Section 4).
3. Event Data Structure
Each drop event is represented as an NDJSON object (types.DropWatchTracing).
| Field | Type | Description |
|---|---|---|
observed_timestamp |
string | UTC timestamp when the event was captured (RFC3339Nano) |
type |
string | Event type reserved field; currently empty string |
drop_reason |
string | Drop reason reserved field; currently empty string |
source |
string | Event source; when present, indicates events or tools (omitempty) |
comm |
string | Process name at the time of the drop |
pid |
uint64 | Process TGID |
container_id |
string | Container ID (populated by huatuo-bamai resolution, omitempty) |
memory_cgroup_css_addr |
string | Memory cgroup CSS address, used for container resolution |
net_namespace_cookie |
uint64 | Network namespace cookie, used for container resolution |
net_namespace_inode |
uint32 | Network namespace inode, used for container resolution |
netdev_name |
string | Network device name (e.g. eth0) |
netdev_ifindex |
uint32 | Network interface index |
netdev_queue_mapping |
uint32 | TX queue mapping |
netdev_linkstatus |
[]string | Network device link status flags |
packet_skb_addr |
string | SKB address (hexadecimal, omitempty) |
packet_eth_proto |
string | Raw EtherType (hexadecimal, e.g. 0x0800) |
packet_len |
uint32 | Packet length in bytes |
layers |
object | Layered protocol parse result; missing layers are omitted |
stack |
string | Kernel call stack (newline-separated) |
layers uses fixed fields to express the protocol stack, without relying on a separate protocol enumeration:
| Field | Description |
|---|---|
layers.label |
Protocol combination label, e.g. IPv4/TCP, IPv6/UDP, ARP, unknown |
layers.ether |
L2 fields: src, dst, type, len (present only for 802.3 frames) |
layers.ipv4 |
IPv4 fields: version, ihl, tos, len, id, flags, frag_offset, ttl, protocol, checksum, src, dst |
layers.ipv6 |
IPv6 fields: version, traffic_class, flow_label, len, next_header, hop_limit, src, dst |
layers.tcp |
TCP fields: sport, dport, seq, ack, data_offset, flags, window, checksum, urgent, sk_state |
layers.udp |
UDP fields: sport, dport, len, checksum |
layers.icmp |
ICMP/ICMPv6 fields: type, code, checksum, id, seq |
layers.arp |
ARP fields: addr_type, protocol, hw_address_size, prot_address_size, operation, sender_mac, sender_ip, target_mac, target_ip |
4. Integration with huatuo-bamai
huatuo-bamai launches dropwatch as a subprocess and uses --output-storage to send events to the built-in processing pipeline, which ultimately stores them in Elasticsearch. Typical parameters:
dropwatch \
--bpf-path <CoreBpfDir>/dropwatch.o \
--output-storage /var/run/huatuo/events.sock \
--filter "tcp"
4.1 Configuration Reference (huatuo-bamai.conf)
[EventTracing]
# Known noisy call-stack filters. dropwatch discards events whose stack matches these regexes.
# The default examples cover neighbor table cleanup and bnxt TX completion SKB frees.
IssuesList = [["neigh_invalidate", "neigh_invalidate"], ["bnxt_tx_int", "bnxt_tx_int"]]
[EventTracing.Dropwatch]
# tcpdump filter expression, forwarded to dropwatch --filter.
# Default: "tcp"
Filter = "tcp"
# Forwarded to dropwatch --max-events-per-second.
# Default: 100
MaxEventsPerSecond = 100
4.2 Noise Filtering
The following three categories of kfree_skb events are filtered by default because they are not real data-plane drops:
| Pattern | Stack Frame Prefix | Reason |
|---|---|---|
TCP CLOSE_WAIT + skb_rbtree_purge |
skb_rbtree_purge/ |
Normal socket teardown: the kernel releases in-flight SKBs when closing a socket in CLOSE_WAIT state. |
| ARP/neighbor table expiry | neigh_invalidate/ |
Neighbor table entry expiration cleanup; does not affect any active data flow. Remove the rule from EventTracing.IssuesList to disable this filter. |
| bnxt NIC TX completion | bnxt_tx_int/ or __bnxt_tx_int/ |
The Broadcom bnxt NIC driver calls kfree_skb to release SKBs after DMA transmit completion; this is normal behavior, not a drop. |
Closing
7 - Development
7.1 - Framework
HuaTuo framework provides three data collection modes: autotracing, event, and metrics, covering different monitoring scenarios, helping users gain comprehensive insights into system performance.
Collection Mode Comparison
| Mode | Type | Trigger Condition | Data Output | Use Case |
|---|---|---|---|---|
| Autotracing | Event-driven | Triggered on system anomalies | ES + Local Storage, Prometheus (optional) | Non-routine operations, triggered on anomalies |
| Event | Event-driven | Continuously running, triggered on preset thresholds | ES + Local Storage, Prometheus (optional) | Continuous operations, directly dump context |
| Metrics | Metric collection | Passive collection | Prometheus format | Monitoring system metrics |
Autotracing
- Type: Event-driven (tracing).
- Function: Automatically tracks system anomalies and dump context when anomalies occur.
- Features:
- When a system anomaly occurs,
autotracingis triggered automatically to dump relevant context. - Data is stored to ES in real-time and stored locally for subsequent analysis and troubleshooting. It can also be monitored in Prometheus format for statistics and alerts.
- Suitable for scenarios with high performance overhead, such as triggering captures when metrics exceed a threshold or rise too quickly.
- When a system anomaly occurs,
- Integrated Features: CPU anomaly tracking (cpu idle), D-state tracking (dload), container contention (waitrate), memory burst allocation (memburst), disk anomaly tracking (iotracer).
Event
- Type: Event-driven (tracing).
- Function: Continuously operates within the system context, directly dump context when preset thresholds are met.
- Features:
- Unlike
autotracing,eventcontinuously operates within the system context, rather than being triggered by anomalies. - Data is also stored to ES and locally, and can be monitored in Prometheus format.
- Suitable for continuous monitoring and real-time analysis, enabling timely detection of abnormal behaviors. The performance impact of
eventcollection is negligible.
- Unlike
- Integrated Features: Soft interrupt anomalies (softirq), memory allocation anomalies (oom), soft lockups (softlockup), D-state processes (hungtask), memory reclamation (memreclaim), packet droped abnormal (dropwatch), network ingress latency (net_rx_latency).
Metrics
- Type: Metric collection.
- Function: Collects performance metrics from subsystems.
- Features:
- Metric data can be sourced from regular procfs collection or derived from
tracing(autotracing, event) data. - Outputs in Prometheus format for easy integration into Prometheus monitoring systems.
- Unlike
tracingdata,metricsprimarily focus on system performance metrics such as CPU usage, memory usage, and network traffic, etc. - Suitable for monitoring system performance metrics, supporting real-time analysis and long-term trend observation.
- Metric data can be sourced from regular procfs collection or derived from
- Integrated Features: CPU (sys, usr, util, load, nr_running, etc.), memory (vmstat, memory_stat, directreclaim, asyncreclaim, etc.), IO (d2c, q2c, freeze, flush, etc.), network (arp, socket mem, qdisc, netstat, netdev, sockstat, etc.).
Multiple Purpose of Tracing Mode
Both autotracing and event belong to the tracing collection mode, offering the following dual purposes:
- Real-time storage to ES and local storage: For tracing and analyzing anomalies, helping users quickly identify root causes.
- Output in Prometheus format: As metric data integrated into Prometheus monitoring systems, providing comprehensive system monitoring capabilities.
By flexibly combining these three modes, users can comprehensively monitor system performance, capturing both contextual information during anomalies and continuous performance metrics to meet various monitoring needs.
7.2 - Add Metrics
Overview
The Metrics type is used to collect system performance and other indicator data. It can output in Prometheus format, serving as a data provider through the /metrics (curl localhost:<port>/metrics) .
-
Type:Metrics collection
-
Function:Collects performance metrics from various subsystems
-
Characteristics:
- Metrics are primarily used to collect system performance metrics such as CPU usage, memory usage, network statistics, etc. They are suitable for monitoring system performance and support real-time analysis and long-term trend observation.
- Metrics can come from regular procfs/sysfs collection or be generated from tracing types (autotracing, event).
- Outputs in Prometheus format for seamless integration into the Prometheus observability ecosystem.
-
Already Integrated:
- cpu (sys, usr, util, load, nr_running…)
- memory(vmstat, memory_stat, directreclaim, asyncreclaim…)
- IO (d2c, q2c, freeze, flush…)
- Network(arp, socket mem, qdisc, netstat, netdev, socketstat…)
How to Add Statistical Metrics
Simply implement the Collector interface and complete registration to add metrics to the system.
type Collector interface {
// Get new metrics and expose them via prometheus registry.
Update() ([]*Data, error)
}
1. Create a Structure
Create a structure that implements the Collector interface in the core/metrics directory:
type exampleMetric struct{
}
2. Register Callback Function
func init() {
tracing.RegisterEventTracing("example", newExample)
}
func newExample() (*tracing.EventTracingAttr, error) {
return &tracing.EventTracingAttr{
TracingData: &exampleMetric{},
Flag: tracing.FlagMetric, // Mark as Metric type
}, nil
}
3. Implement the Update Method
func (c *exampleMetric) Update() ([]*metric.Data, error) {
// do something
...
return []*metric.Data{
metric.NewGaugeData("example", value, "description of example", nil),
}, nil
}
The core/metrics directory in the project has integrated various practical Metrics examples, along with rich underlying interfaces provided by the framework, including BPF program and map data interaction, container information, etc. For more details, refer to the corresponding code implementations.
7.3 - Add Event
Overview
- Type: Exception event-driven(tracing/event)
- Function:Continuously runs in the system and captures context information when preset thresholds are reached
- Characteristics:
- Unlike
autotracing,eventruns continuously rather than being triggered only when exceptions occur. - Event data is stored locally in real-time and also sent to remote ES. You can also generate Prometheus metrics for observation.
- Suitable for continuous monitoring and real-time analysis, enabling timely detection of abnormal behaviors in the system. The performance impact of
eventtype collection is negligible.
- Unlike
- Already Integrated: Soft interrupt abnormalities(softirq)、abnormal memory allocation(oom)、soft lockups(softlockup)、D-state processes(hungtask)、memory reclaim(memreclaim)、abnormal packet loss(dropwatch)、network inbound latency (net_rx_latency), etc.
How to Add Event Metrics
Simply implement the ITracingEvent interface and complete registration to add events to the system.
There is no implementation difference between
AutoTracingandEventin the framework; they are only differentiated based on practical application scenarios.
// ITracingEvent represents a tracing/event
type ITracingEvent interface {
Start(ctx context.Context) error
}
1. Create Event Structure
type exampleTracing struct{}
2. Register Callback Function
func init() {
tracing.RegisterEventTracing("example", newExample)
}
func newExample() (*tracing.EventTracingAttr, error) {
return &tracing.EventTracingAttr{
TracingData: &exampleTracing{},
Internal: 10, // Interval in seconds before re-enabling tracing
Flag: tracing.FlagTracing, // Mark as tracing type; | tracing.FlagMetric (optional)
}, nil
}
3. Implement the ITracingEvent Interface
func (t *exampleTracing) Start(ctx context.Context) error {
// do something
...
// Store data to ES and locally
storage.Save("example", ccontainerID, time.Now(), tracerData)
}
Additionally, you can optionally implement the Collector interface to output in Prometheus format:
func (c *exampleTracing) Update() ([]*metric.Data, error) {
// from tracerData to prometheus.Metric
...
return data, nil
}
The core/events directory in the project has integrated various practical events examples, along with rich underlying interfaces provided by the framework, including BPF program and map data interaction, container information, etc. For more details, refer to the corresponding code implementations.
7.4 - Add Autotracing
Overview
- Type:Exception event-driven(tracing/autotracing)
- Function:Automatically tracks system abnormal states and triggers context information capture when exceptions occur
- Characteristics:
- When system abnormalities occur,
autotracingautomatically triggers and captures relevant context information - Event data is stored locally in real-time and also sent to remote ES, while you can also generate Prometheus metrics for observation
- Suitable for significant performance overhead, such as triggering capture when detecting metrics rising above certain thresholds or rising too rapidly
- When system abnormalities occur,
- Already Integrated:abnormal usage tracking (cpu idle), D-state tracking (dload), container internal/external contention (waitrate), sudden memory allocation (memburst), disk abnormal tracking (iotracer)
How to Add Autotracing
AutoTracing only requires implementing the ITracingEvent interface and completing registration to add events to the system.
There is no implementation difference between
AutoTracingandEventin the framework; they are only differentiated based on practical application scenarios.
// ITracingEvent represents a autotracing or event
type ITracingEvent interface {
Start(ctx context.Context) error
}
1. Create Structure
type exampleTracing struct{}
2. Register Callback Function
func init() {
tracing.RegisterEventTracing("example", newExample)
}
func newExample() (*tracing.EventTracingAttr, error) {
return &tracing.EventTracingAttr{
TracingData: &exampleTracing{},
Internal: 10, // Interval in seconds before re-enabling tracing
Flag: tracing.FlagTracing, // Mark as tracing type; | tracing.FlagMetric (optional)
}, nil
}
3. Implement ITracingEvent
func (t *exampleTracing) Start(ctx context.Context) error {
// detect your care about
...
// Store data to ES and locally
storage.Save("example", ccontainerID, time.Now(), tracerData)
}
Additionally, you can optionally implement the Collector interface to output in Prometheus format:
func (c *exampleTracing) Update() ([]*metric.Data, error) {
// from tracerData to prometheus.Metric
...
return data, nil
}
The core/autotracing directory in the project has integrated various practical autotracing 示examples, along with rich underlying interfaces provided by the framework, including BPF program and map data interaction, container information, etc. For more details, refer to the corresponding code implementations.
7.5 - Integration Test
This integration test validates that huatuo-bamai can start correctly with mocked /proc and /sys filesystems and expose the expected Prometheus metrics.
The test runs the real huatuo-bamai binary and verifies the /metricsendpoint output without relying on the host kernel or hardware.
What the Script Does
The integration test performs the following steps:
- Generates a temporary
bamai.conf - Starts
huatuo-bamaiwith mockedprocfsandsysfs - Waits for the Prometheus
/metricsendpoint to become available - Fetches all metrics from
/metrics - Verifies that all expected metrics exist
- Stops the service and cleans up resources
If any expected metric is missing, the test fails.
How to Run
Run the integration test from the project root:
bash integration/run.sh
or
make integration
On Failure
- The
huatuo-bamaiservice metrics and logs are printed to stdout - The temporary working directory is kept for debugging
On Success
- Output the list of successfully validated metrics
How to Add New Metrics Tests
1: Add or Update Fixture Data
If the metric depends on /proc or /sys, add or update mock data under:
integration/fixtures/
The directory structure should match the real kernel filesystem layout.
2: Add Expected Metrics
Create a new file under:
integration/fixtures/expected_metrics/
├── cpu.txt
├── memory.txt
└── ...
Each non-empty, non-comment line represents one expected Prometheus metric line and must match the /metrics output exactly.
New *.txt files are automatically picked up by the test.
3: Run the Test
bash integration/run.sh
The test fails if any expected metric is missing or mismatched.
8 - FAQ
Metrics
-
Why do the
memory_others_*metrics (e.g.directstall_time) have no data?The
memory_otherscollector reads memory cgroup extension interfaces provided by the Didi Cloud custom kernel (memory.directstall_stat,memory.asynreclaim_stat,memory.local_direct_reclaim_time). Mainline and common distribution kernels do not expose these interfaces, and no loadable kernel module provides them, so these metrics are simply not emitted on standard kernels — this is expected behavior.To observe container direct reclaim behavior on standard kernels, use the eBPF-based
memory_reclaim_container_directstallmetric instead; see the Memory System section in “Key Features / Kernel-Wide Insight”.
9 - Contribute
9.1 - Code Contributions
Contributing to HUATUO
Thank you for your interest in contributing to HUATUO! This guide will help you get started.
Ways to Contribute
There are many ways to contribute to HUATUO:
- Code — Fix bugs, add features, improve performance
- Documentation — Improve docs, translate content, write tutorials
- Testing — Write unit tests, integration tests, report bugs
- eBPF — Add new kernel probes, improve kernel compatibility
- Review — Review pull requests from other contributors
Development Environment
Prerequisites
| Tool | Requirement | Note |
|---|---|---|
| Go | 1.24+ | The project is written in Go |
| Linux | Kernel 4.18+ | eBPF programs require a Linux kernel |
| Clang/LLVM | Any recent version | Required for compiling eBPF C programs |
| Kernel headers | linux-headers | Required for BPF compilation |
| Docker | (optional) | For containerized development |
| Git | Any recent version | For version control |
Clone the Repository
# Fork the repository on GitHub, then:
git clone https://github.com/YOUR_USERNAME/huatuo.git
cd huatuo
git remote add upstream https://github.com/ccfos/huatuo.git
Build and Test
Build
make all # Build everything (BPF + Go)
make bpf-build # Build only BPF programs
make build # Build only Go binaries
make docker-build # Build Docker image
Test
make test # Run all tests
make unit # Run unit tests only
make check # Run linting and formatting checks
Note:
make testrequires/etc/kubernetes/pkifor E2E tests. If you don’t have a K8s cluster, usemake unitinstead.
Contribution Workflow
1. Find or Create an Issue
- Check the open issues for bugs and features
- If you find an unassigned issue, comment to ask for assignment
- If you have a new idea, create an issue first
2. Create a Branch
git checkout -b fix/short-description
# or: git checkout -b feat/short-description
# or: git checkout -b docs/short-description
Branch name prefixes:
| Prefix | Purpose |
|---|---|
fix/ |
Bug fixes |
feat/ |
New features |
docs/ |
Documentation |
refactor/ |
Code restructuring |
test/ |
Adding tests |
3. Make Your Changes
- Keep changes focused on a single issue
- Add or update tests to cover your changes
- Run
make checkto ensure code style compliance - Run
make unitto verify tests pass
4. Commit Your Changes
Use conventional commits:
git commit -s -m "fix(scope): brief description
Detailed explanation if needed.
Closes #issue-number
Signed-off-by: Your Name <your.email@example.com>"
The -s flag adds the required DCO Signed-off-by line.
5. Push and Create a Pull Request
git push origin your-branch-name
Then go to ccfos/huatuo and create a draft Pull Request. When ready for review, click Ready for review.
6. Code Review
- A maintainer will review your PR
- Address review comments by pushing new commits
- Once approved, the maintainer will merge your PR
Commit Messages
HUATUO follows Conventional Commits:
<type>(<scope>): <description>
[optional body]
[optional footer]
Types
| Type | Description |
|---|---|
fix |
A bug fix |
feat |
A new feature |
docs |
Documentation changes |
test |
Adding or updating tests |
refactor |
Code restructuring without behavior change |
chore |
Build process, dependencies, etc. |
perf |
Performance improvements |
Examples
fix(pod): preserve response body read errors in httpDoRequest
feat(bpf): add probe for kernel scheduling latency
docs(contributing): add development setup guide
test(request): verify response body is readable after doRequest
Code Style
| Language | Tool |
|---|---|
| Go | gofumpt + goimports |
| C (eBPF) | clang-format (config in .clang-format) |
| Shell | shfmt |
| YAML/JSON | 2-space indent |
Run make check before every commit to ensure compliance.
DCO Sign-off
All contributions must include a Developer Certificate of Origin (DCO) sign-off.
Every commit must end with:
Signed-off-by: Your Name <your.email@example.com>
Use git commit -s to add this automatically.
The sign-off certifies that you wrote the code or have the right to contribute it under the project’s license (Apache 2.0).
Community
- GitHub Issues — Report bugs and request features
- GitHub Discussions — Ask questions and share ideas
- WeChat — Scan the QR code in the README to join the group
Thank you for contributing to HUATUO!